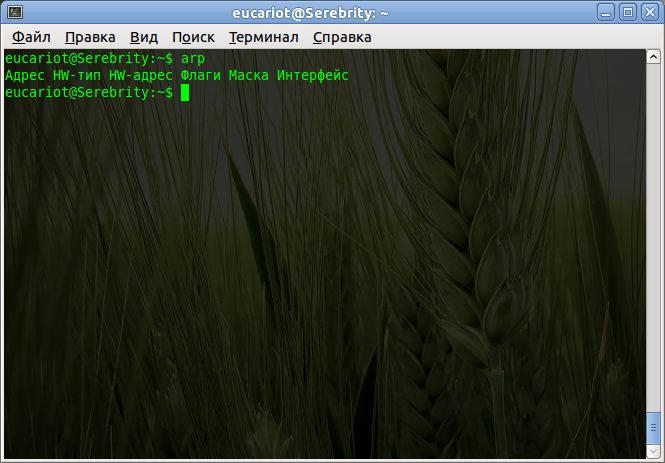
Всем привет! Статическая маршрутизация – это по сути специальный выделенный путь, по которому должен пройти пакет информации из пункта А в пункт Б. Напомню, что у нас в сети чаще всего встречаются два устройства: маршрутизаторы и коммутаторы. Напомню, что коммутаторы работают на канальном уровне, а маршрутизаторе на сетевом. Далее я коротко расскажу, про Static Route и как это настроить на домашнем устройстве.
Содержание
- Коротко про маршрутизацию
- ШАГ 1: Заходим в настройки роутера
- ШАГ 2: Настройка
- TP-Link
- D-Link
- ASUS
- ZyXEL Keenetic
- Netis
- Tenda
- Задать вопрос автору статьи
Коротко про маршрутизацию
Маршрутизатор, исходя из названия, имеет у себя таблицу маршрутизации, а коммутатор коммутации. Все логично, не правда ли. Но есть небольшая проблема коммутации. Представим, что у нас есть две сети по 250 машин и между ними стоят 2 свича.
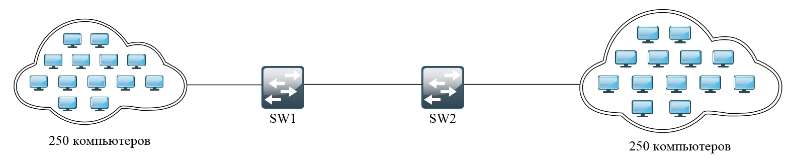
Если вы помните в таблице коммутации содержатся MAC-адреса. Да они уникальны, поэтому для работы сети нужно, чтобы каждый свич знал, как минимум 500 таких адресов, что не так мало. И тут встает проблема масштабируемости сети, при добавлении новых машин.
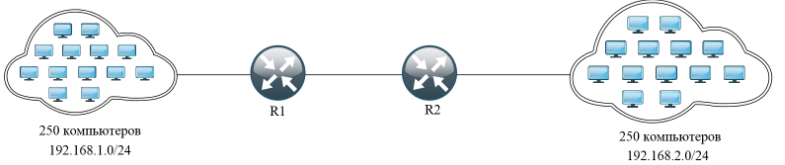
А что если установить вместо коммутаторов маршрутизаторы. В итоге у нас есть две сети:
- 192.168.1.0/24
- 192.168.2.0./24
И чтобы пакету добраться из одной сети в другую, нужна одна запись в таблице маршрутизации, а именно о соседнем роутере, который уже в свою очередь знает компьютеры «из своего района». Это и удобно, и экономично в плане хранения нужной информации, так как не нужно хранить таблицу из MAC-адресов всех участников сети.
СОВЕТ! Для большей картины понимания самой темы, советую почитать дополнительные материалы про то, что такое маршрутизатор, коммутатор и про модель OSI.
И тут у нас появляются два понятия:
- Динамическая маршрутизация – когда при отправке информации через маршрутизатор он в свою очередь сообщает доступность других соседних маршрутизаторов или сетей, и куда можно отправить пакет. Если говорить грубо, то информация идет тем путем, как ему показывают роутеры.
- Статическая маршрутизация – пакет информации идет определенным путем. Данный маршрут можно прописать вручную.
Далее я расскажу, как вводить эти статические маршруты для использования их в домашних роутерах.
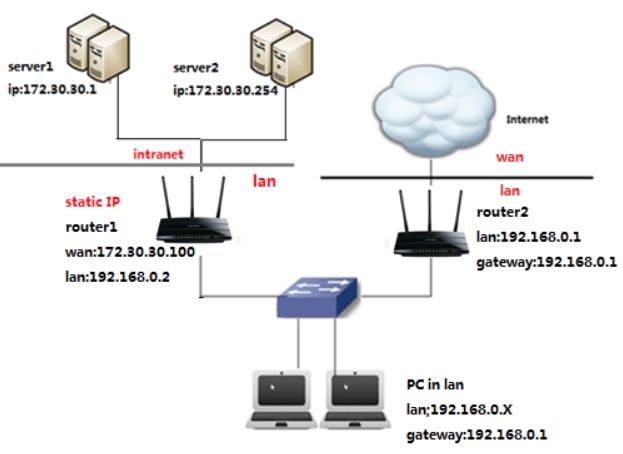
Смотрим на картинку выше. У нас есть второй роутер (router 2), который имеет доступ к интернету (он же является основным шлюзом). У нас есть компьютер (PC), который подключен сначала к коммутатору. Коммутатор подключен к двум роутерам.
Проблема в том, что ПК должен иметь доступ к серверу (172.30.30.1), но при запросе на router 2, у него в таблице маршрутизации нет данных об этих серверах. Теперь давайте попробуем вписать эти настройки в маршрутизатор.
ШАГ 1: Заходим в настройки роутера
Вот мы и перешли непосредственно к настройке статической маршрутизации. Подключаемся к сети интернет-центра через кабель или по Wi-Fi. Далее нужно ввести DNS или IP-адрес роутера в адресную строку любого браузера. Настройку мы будем делать через Web-интерфейс. Подсказка: адрес можно подсмотреть на этикетке под корпусом аппарата. Чаще всего используют адреса:
- 192.168.1.1
- 192.168.0.1
Если вы ранее его настраивали, вводим логин и пароль – их также можно подсмотреть на той же самой бумажке. Чаще всего используют комбинации:
- admin – admin
- admin – *Пустая строка*
Если есть проблемы со входом в роутер, то смотрим инструкцию тут.
ШАГ 2: Настройка
Напомню, что далее я буду рассматривать конкретный пример, который мы разобрали выше. И на основе этого примера буду вводить свои данные. У вас статические маршруты могут быть другие. Вот какие данные нужно будет ввести (смотрим на схему подключения, чтобы вам было понятно):
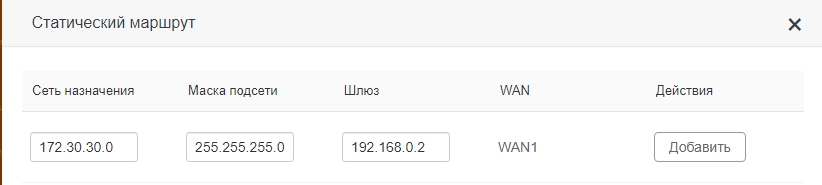
- IP адрес назначения – у нас это IP нашего конкретного сервера, к которому мы хотим пробиться через наш 1-ый роутер (172.30.30.1).
- Маска подсети – указываем 255.255.255.0.
- Шлюз – это IP того роутера, который имеет доступ к серверу. В примере это 192.168.0.2 (Второй маршрутизатор).
- Интерфейс – в некоторых настройках нужно будет указывать еще и его. Если доступ к шлюзу идет через интернет, то указываем WAN. Если же вы подключены к нему через LAN порт (как в нашем примере), то указываем его.
Надеюсь я примерно объяснил, как именно статический маршрут нужно заполнять. Теперь приступим непосредственно к практике. Смотрите главу по своей модели.
TP-Link
Старая прошивка
Слева находим раздел «Дополнительные настройки маршрутизации», и в открывшемся списке нажимаем по пункту «Список статических маршрутов». Нажимаем по кнопке «Добавить».
Вписываем данные.
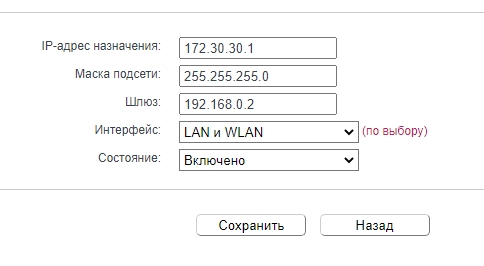
Новая прошивка
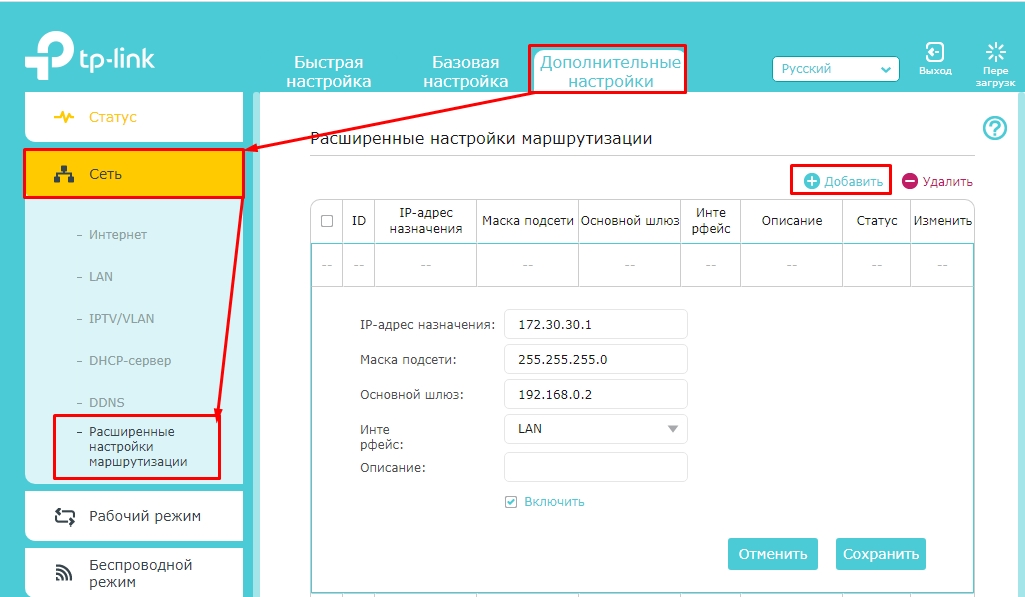
«Дополнительные настройки» – «Сеть» – «Расширенные настройки маршрутизации». Нажимаем по плюсику и вписываем нужную информацию.
D-Link
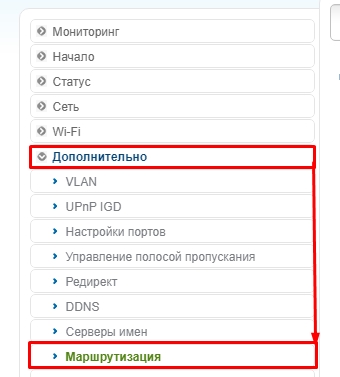
В классическом светлом интерфейсе нужно перейти в «Дополнительно» и нажать по «Маршрутизации».
В темной прошивке все делается также, только сначала нужно перейти в «Расширенные настройки».
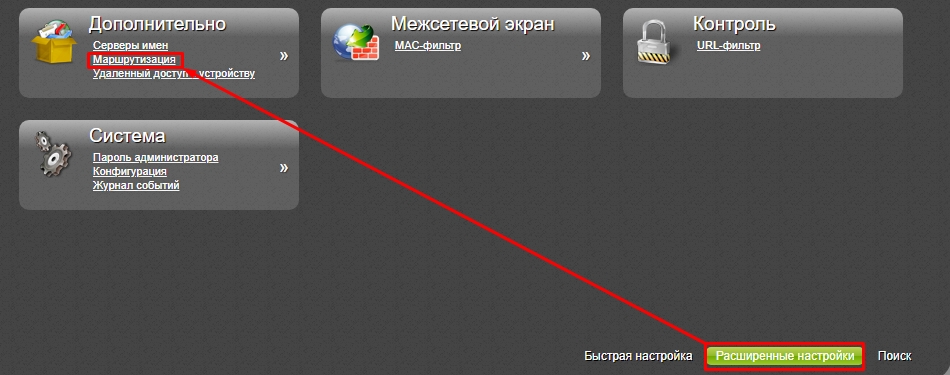
Добавляем правило.
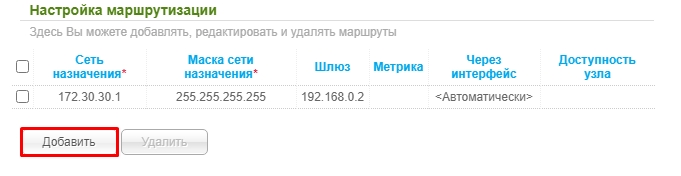
ASUS
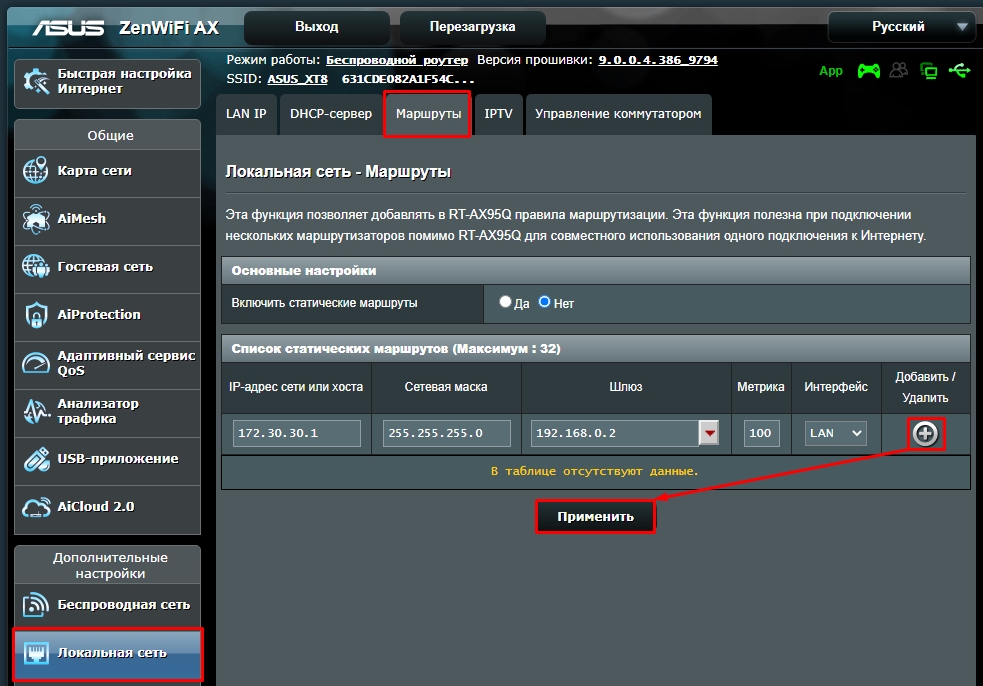
Переходим в раздел «Локальная сеть», открываем вкладку «Маршруты» и вписываем наши данные. В конце не забудьте нажать на плюсик, правее таблички и нажать на кнопку «Применить».
ZyXEL Keenetic
Новая прошивка
Переходим на страницу «Маршрутизации» и нажимаем по кнопке добавления правила.
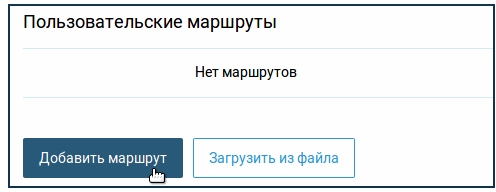
Теперь вводим данные:
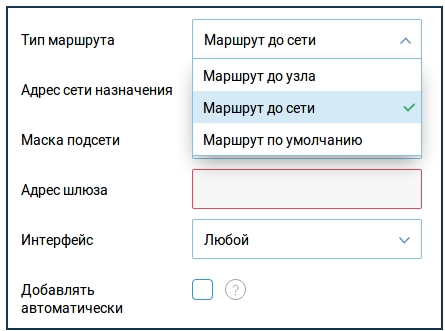
- Тип маршрута – тут нужно указывать тот тип, который вам нужен. Если исходить из задачи, которую указал я, то мы указываем «Маршрут узла».
- Адрес сети назначения – указываем адрес сервера. В нашем случае это 30.30.1.
- Маска подсети – 255.255.255.0.
- Адрес шлюза – адрес роутера, который подключен к нашему серверу. 192.168.0.2.
- Интерфейс – указываем тот интерфейс, который мы будем использовать для связи. В нашем примере пакеты пойдут локально через LAN порт, поэтому указываем LAN.
Старая прошивка
Нажимаем по значку плакетки в самом низу и переходим на вкладку «Маршруты». Нажимаем по кнопке добавления и вводим нужные вам данные.
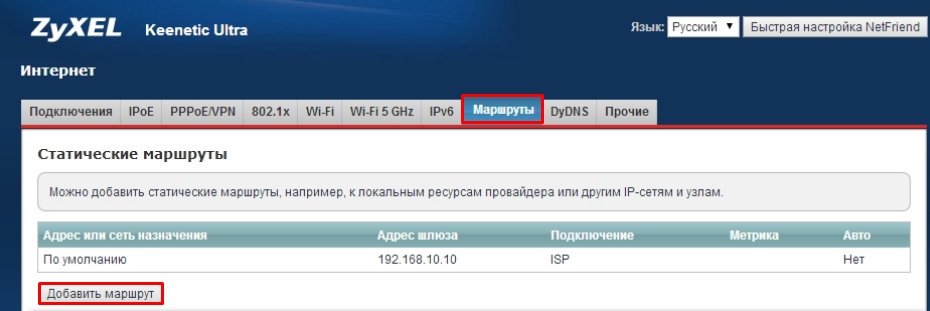
Добавление целого списка маршрутов
Кстати тут вы можете загрузить сразу целую таблицу маршрутизации. Для этого выбираем в том же разделе другую кнопку.
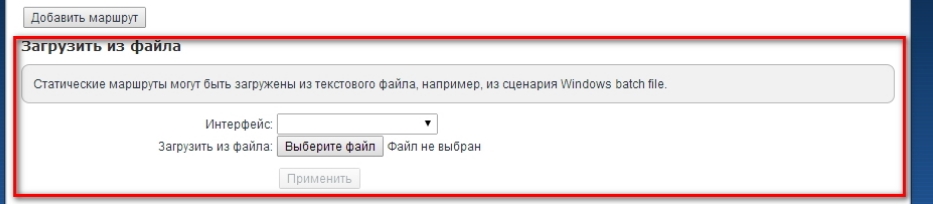
Файлик должен иметь расширение типа BAT. И иметь вид как на скрине ниже. Его спокойно можно создать в блокноте.

Вид достаточно простой:
route ADD IP-адрес назначения MASK указываем маску указываем адрес шлюза
Пример:
route ADD 172.30.30.1 MASK 255.255.255.0 192.168.0.2
ПРИМЕЧАНИЕ! Каждый новый адрес должен начинаться с новой строки, а после последнего указанного IP не должен стоять пробел.
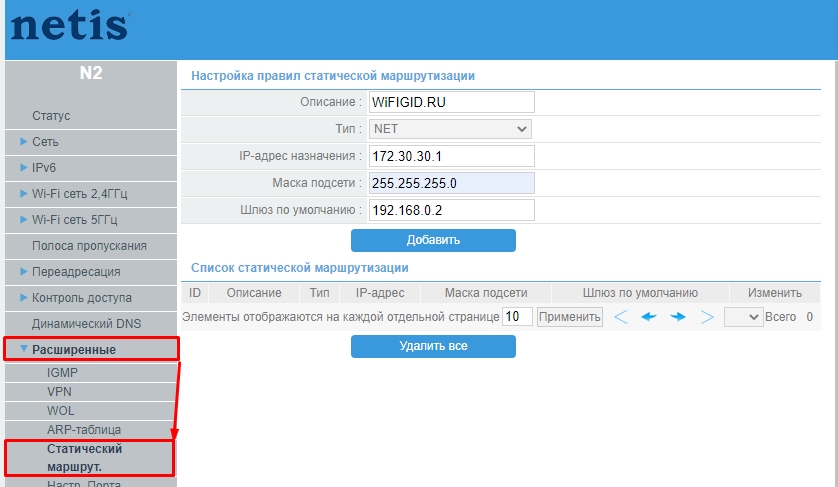
Netis
Переходим в раздел «Advanced» (кнопкам в правом верхнем углу) – «Расширенные» – «Статический маршрут.» – вводим каждый пункт и нажимаем по кнопке «Добавить».
Tenda
Нужный нам пункт находится в разделе «Расширенные настройки».
Как настроить статическую маршрутизацию на беспроводном роутере?
Требования к использованию
Дата последнего обновления: 05-28-2019 08:15:03 AM
![]() 555662
555662
Эта статья подходит для:
TL-WR841ND , TL-WR842ND , TL-WR843ND , Archer C5( V1.20 ) , Archer C2( V1 ) , Archer C50( V1 ) , TL-WDR3500 , TL-WR720N , TL-WR841N , TL-WDR3600 , TL-WR710N , TL-WR740N , Archer C20i , TL-WR741ND , TL-WR940N , TL-WR743ND , TL-WR1043ND , Archer C7( V1 V2 V3 ) , TL-WR1042ND , TL-WR542G , TL-WR702N , TL-WR700N , TL-WR843N , TL-WR340G , TL-WDR4300 , TL-WR340GD , Archer C20( V1 ) , TL-MR3220 , TL-WR842N , TL-WR2543ND , TL-MR3020 , TL-WR840N , TL-MR3040 , TL-WR841HP , TL-WDR4900 , TL-WR941ND , TL-WR543G , TL-WR541G , TL-WR810N , TL-MR3420
Статический маршрут — это заранее определенный путь, по которому должна следовать информация в сети, чтобы достичь определенного хоста или сети.
Вот два типичных сценария, в качестве примеров, когда требуется статический маршрут, рассмотрим их.
Сценарий 1:
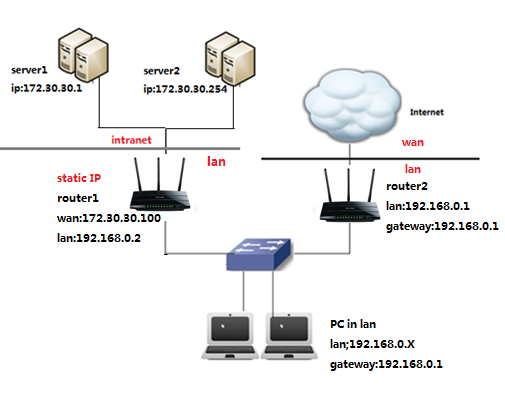
Проблема:
Шлюзом ПК-является роутер 2, который предоставляет доступ в интернет.
Когда ПК хочет подключиться к серверам сервер 1 и сервер 2, сначала запрос будет отправлен на роутер 2. Поскольку к сервер 1 и сервер 2 нет маршрута в таблице маршрутов роутера 2, запрос будет отклонен.
Решение: Добавление статического маршрута на роутере 2
Сетевые параметры: Серверы в сетевом сегменте: 172.30.30.0. Маска подсети IP для этого сегмента: 255.255.255.0
Сценарий 2:
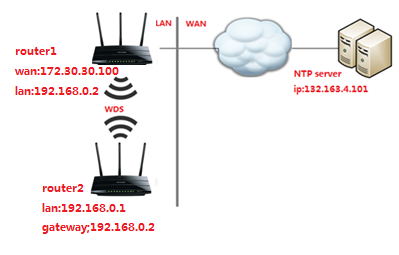
Проблема: Шлюзом сети LAN является роутер 1, роутер 2 подключен по WDS к роутеру 1. В таблице маршрутизации роутера 2 нет записи маршрута от роутера 2 к NTP-серверу, поэтому роутер 2 не может синхронизировать время с NTP сервером.
Разрешение: Добавление статического маршрута на роутере 2
Сетевые параметры: IP-адрес сервера в Интернете — 132.163.4.101. Маска подсети IP для этого адреса 255.255.255.255
Шаги настройки:
Шаг 1.
Зайдите на web – страницу настройки роутера.
Для этого в адресной строке браузера наберите 192.168.0.1

Шаг 2. Введите имя пользователя и пароль на странице входа. Имя пользователя и пароль по умолчанию — admin.
Шаг 3. В меню с левой стороны выберите раздел Настройки маршрутизации – Список статических маршрутов.

Шаг 4.
Нажмите Добавить ….
В первом поле введите IP-адрес назначения.
В втором поле введите маску подсети.
В третьем поле IP-адрес шлюза, который должен находиться в том же сегменте локальной сети, что и роутер.

Пример ввода параметров для Сценария 1:

Пример ввода параметров для Сценария 2:

Если у Вас возникнуть какие либо сложности с настройкой, обратитесь в техническую поддержку TP-Link
Чтобы получить подробную информацию о каждой функции и настройке оборудования, перейдите на страницу Загрузки для загрузки руководства пользователя к вашей модели устройства.
Был ли этот FAQ полезен?
Ваш отзыв поможет нам улучшить работу сайта.
Что вам не понравилось в этой статье?
- Недоволен продуктом
- Слишком сложно
- Неверный заголовок
- Не относится к моей проблеме
- Слишком туманное объяснение
- Другое
Как мы можем это улучшить?
Спасибо
Спасибо за обращение
Нажмите здесь, чтобы связаться с технической поддержкой TP-Link.
Маршрутизация — процесс поиска оптимального пути для передачи пакетов в сетях TCP/IP. Любой устройство подключенное к сети IPv4 содержит процесс и таблицы маршрутизации.
Данная статья не является HOWTO, она описывает на примерах статическую маршрутизацию в RouterOS, я намеренно опускал остальные настройки (например srcnat для доступа в сеть интернет), поэтому для понимания материала требуется определенный уровень знания по сетям и RouterOS.
Коммутация и маршрутизация

Коммутация — процесс обмена пакетами в пределах одного Layer2 сегмента (Ethernet, ppp, …). Если устройство видит, что получатель пакета находится с ним в одной Ethernet подсети, оно узнает mac адрес по протоколу arp и передает пакет напрямую, минуя маршрутизатор. У ppp (point-to-point) соединения может быть только два участника и пакет всегда отправляется на один адрес 0xff.
Маршрутизация — процесс передачи пакетов между Layer2 сегментами. Если устройство хочет отправить пакет, получатель которого находится за пределами Ethernet сегмента, оно смотрит в свою таблицу маршрутизации и передает пакет шлюзу, который знает куда отправить пакет дальше (а может и не знает, изначальный отправитель пакета про это не осведомлен).
Проще всего рассматривать маршрутизатор, как устройство подключенное к двум или более Layer2 сегментам и способное передавать пакеты между ними определяя оптимальный маршрут по таблице маршрутизации.
Если вам все понятно или вы и так это знали, то читайте дальше. Остальным настоятельно рекомендую ознакомиться с маленькой, но очень емкой статьей.
Маршрутизация в RouterOS и PacketFlow
Практически весь функционал относящийся к статической маршрутизации находится в пакете system. Пакет routing добавляет поддержку алгоритмов динамической маршрутизации (RIP, OSPF, BGP, MME), Routing Filters и BFD.
Основное меню для настройки маршрутизации: [IP]->[Route]. Сложные схемы могут потребовать предварительную маркировку пакетов маршрутной меткой в: [IP]->[Firewall]->[Mangle] (цепочки PREROUTING и OUTPUT).
На PacketFlow можно выделить три места, где принимаются решения о маршрутизации IP пакетов:
- Маршрутизация пакетов поступивших на роутер. На данном этапе решается уйдет пакет локальному процессу или будет отправлен дальше в сеть. Транзитные пакеты получают Output Interface
- Маршрутизация локальных исходящих пакетов. Исходящие пакеты получают Output Interface
- Дополнительный этап маршрутизации для исходящих пакетов, позволяет изменить решение о маршрутизации в
[Output|Mangle]
- Путь пакета в блоках 1, 2 зависит от правил в
[IP]->[Route] - Путь пакета в пунктах 1, 2 и 3 зависит от правил в
[IP]->[Route]->[Rules] - На путь пакета в блоках 1, 3 можно повлиять используя
[IP]->[Firewall]->[Mangle]
RIB, FIB, Routing Cache
Routing Information Base
База в которой собираются маршруты от протоколов динамической маршрутизации, маршруты от ppp и dhcp, статические и подключенные (connected) маршруты. Данная база содержит все маршруты, за исключением отфильтрованных администратором.
Условно, можно считать что [IP]->[Route] отображает RIB.
Forwarding Information Base
База в которой собираются наилучшие маршруты из RIB. Все маршруты в FIB являются активными и используются для пересылки пакетов. Если маршрут становится неактивным (отключен администратором (системой), или интерфейс через который должен отправляться пакет не активен) маршрут удаляется из FIB.
Для принятия решения о маршрутизации в таблице FIB используются следующие данные о IP пакете:
- Source Address
- Destination Address
- Source Interface
- Routing mark
- ToS (DSCP)
Попадая в FIB пакет проходит следующие стадии:
- Пакет предназначен локальному процессу роутера?
- Пакет попадает под системные или пользовательские правила PBR?
- Если да, то пакет отправляется в указанную таблицу маршрутизации
- Пакет отправляется в таблицу main
Условно, можно считать что [IP]->[Route Active=yes] отображает FIB.
Routing Cache
Механизм кэширования маршрутов. Маршрутизатор запоминает куда были отправлены пакеты и если встречаются похожие (предположительно из одного соединения) пускает их по тому-же маршруту, без проверки в FIB. Кэш маршрутов периодически очищается.
Для администраторов RouterOS не сделали средств просмотра и управления Routing Cache, но при его можно отключить в [IP]->[Settings].
Данный механизм был удален из ядра linux 3.6, но в RouterOS до сих пор используется kernel 3.3.5, возможно Routing cahce — одна из причин.
Диалог добавления маршрута
[IP]->[Route]->[+]
- Подсеть для которой необходимо создать маршрут (по умолчанию: 0.0.0.0/0)
- IP шлюза или интерфейс на который будет отправлен пакет (может быть несколько, см. ниже ECMP)
- Проверка доступности шлюза
- Тип записи
- Дистанция (метрика) для маршрута
- Таблица маршрутизации
- IP для локальных исходящих пакетов через данный маршрут
- Про назначение Scope и Target Scope написано в конце статьи
Флаги маршрутов
- X — Маршрут отключен администратором (
disabled=yes) - A — Маршрут используется для передачи пакетов
- D — Маршрут добавлен динамически (BGP, OSPF, RIP, MME, PPP, DHCP, Connected)
- C — Подсеть подключена непосредственно к маршрутизатору
- S — Статический маршрут
- r,b,o,m — Маршрут добавлен одним из протоколов динамической маршрутизации
- B,U,P — Фильтрующий маршрут (отбрасывает пакеты вместо передачи)
Что указывать в gateway: ip-адрес или интерфейс?
Система позволяет указывать и то, и другое, при этом не ругается и не дает подсказок, если вы что-то сделали неправильно.
IP адрес
Адрес шлюза должен быть доступен по Layer2. Для Ethernet это означает, что роутер должен иметь на одном из активных интерфейсов ip адрес из той же подсети, для ppp — что адрес gateway указан на одном из активных интерфейсов в качестве адреса подсети.
Если условие доступности по Layer2 не выполняется — маршрут считается неактивным и не попадает в FIB.
Интерфейс
Все сложнее и поведение маршрутизатора зависит от типа интерфейса:
- PPP (Async, PPTP, L2TP, SSTP, PPPoE, OpenVPN*) соединение предполагает наличие только двух участников и пакет всегда будет направлен шлюзу для передачи, если шлюз обнаружит, что получателем является он сам, то передаст пакет своему локальному процессу.

- Ethernet предполагает наличие множества участников и будет отправлять на интерфейс arp запросы с адресом получателя пакета, это ожидаемое и вполне нормальное поведение для connected маршрутов.
Но при попытке использовать интерфейс в качестве маршрута для удаленной подсети вы получите следующую ситуацию: маршрут активен, ping до шлюза проходит, но не доходят до получателя из указанной подсети. Если посмотрите на интерфейс через сниффер, то увидите arp запросы с адресами из удаленной подсети.
Старайтесь указывать ip адрес в качестве gateway всегда когда это возможно. Исключение — connected маршруты (создаются автоматически) и PPP (Async, PPTP, L2TP, SSTP, PPPoE, OpenVPN*) интерфейсы.
OpenVPN не содержит PPP заголовка, но можно использовать имя OpenVPN интерфейса для создания маршрута.
More Specific Route
Основное правило маршрутизации. Маршрут описывающий более маленькую подсеть (с наибольшей маской подсети) имеет больший приоритет при принятии решения о маршрутизации пакета. Положение записей в таблице маршрутизации не имеет отношения к выбору — основное правило More Specific.
Все маршруты из указанной схемы активны (находятся в FIB), т.к. указывают на различные подсети и не конфликтуют между собой.
Если один из шлюзов станет недоступным, связанный маршрут будет считаться неактивным (удален из FIB) и для пакетов будет производиться поиск из оставшихся маршрутов.
Маршруту с подсетью 0.0.0.0/0 иногда придают особое значение и называют «Маршрут по умолчанию» (Default Route) или «Шлюз последней надежды» (gateway of last resort). На самом деле в нем нет ничего магического и он просто включает все возможные адреса IPv4, но данные названия хорошо описывают его задачу — он указывает на шлюз, куда пересылать пакеты для которых нет других, более точных, маршрутов.
Максимально возможная маска подсети для IPv4 — /32, такой маршрут указывает на конкретный хост и может использоваться в таблице маршрутизации.
Понимание More Specific Route является фундаментальным для любых устройств работающих с TCP/IP.
Distance
Дистанции (или Метрики) необходимы для административной фильтрации маршрутов до одной подсети доступной через несколько шлюзов. Маршрут с меньшей метрикой считается приоритетным и попадет в FIB. Если маршрут с меньшей метрикой перестанет быть активным, то в FIB он будет заменен на маршрут с большей метрикой.
Если присутствует несколько маршрутов до одной подсети с одинаковой метрикой, маршрутизатор добавить в таблицу FIB только один из них, руководствуясь своей внутренней логикой.
Метрика может принимать значение от 0 до 255:
- 0 — Метрика для подключенных (connected) маршрутов. Дистанция 0 не может быть выставлена администратором
- 1-254 — Метрики доступные администратору для установки маршрутам. Метрики с меньшим значением имеют больший приоритет
- 255 — Метрика доступная администратору для установки маршрутам. В отличии от 1-254, маршрут с метрикой 255 всегда остается неактивным и не попадает в FIB
- Особые метрики. У маршрутов полученных от протоколов динамической маршрутизации, есть стандартные значения метрик
Check gateway
Check gateway — расширение MikroTik RoutesOS для проверки доступности шлюза по icmp или arp. Раз в 10 секунд (изменить нельзя) на шлюз отправляется запрос, если дважды не приходит ответ маршрут считается недоступным и удаляется из FIB. Если check gateway отключил маршрут проверки продолжается и маршрут снова станет активным после одной успешной проверки.
Check gateway отключает запись, в которой он настроен и все остальные записи (во всех таблицах маршрутизации и ecmp маршрутах) с указанным шлюзом.
В целом check gateway работает нормально, если не возникает проблем с потерей пакетов до шлюза. Check gateway не знает, что происходит со связью за пределами проверяемого шлюза, для этого необходимы дополнительные инструменты: скрипты, рекурсивная маршрутизация, протоколы динамической маршрутизации.
Большинство VPN и туннельных протоколов содержат встроенные средства для проверки активности соединения, включать для них check gateway — это дополнительная (но очень маленькая) нагрузка на сеть и производительность устройства.
ECMP маршруты
Equal-Cost Multi-Path — отправка пакетов до получателя используя одновременно несколько шлюзом с перебором по алгоритму Round Robin.
ECMP маршрут создается администратором, путем указания нескольких gateway для одной подсети (либо автоматический, при наличии двух равноценных маршрутов OSPF).
ECMP используется для балансировки нагрузки между двумя каналами, в теории, если в ecmp маршруте два канала, то для каждого пакета исходящий канал должен отличаться. Но механизм Routing cache отправляет пакеты из соединения по маршруту, которым пошел первый пакет, в итоге получаем подобие балансировки на базе соединений (per-connection loading balancing).
Если отключить Routing Cache, то пакеты в ECMP маршруте будут делиться правильно, но возникает проблема с NAT. Правило NAT обрабатывает только первый пакет из соединения (остальные обрабатываются автоматически) и получается ситуация, что с различных интерфейсов уходят пакеты с одним адресом источника.
В ECMP маршрутах не работает check gateway (баг RouterOS). Но можно обойти это ограничение, если создать дополнительные маршруты для проверки, которые будут отключать записи в ECMP.
Фильтрация средствами Routing
Опция Type определяет, что сделать с пакетом:
- unicast — отправить на указанный шлюз (интерфейс)
- blackhole — отбросить пакет
- prohibit, unreachable — отбросить пакет и отправить icmp сообщение отправителю
Фильтрацию обычно используют, когда нужно обезопасить отправку пакетов не по тому пути, конечно можно фильтровать подобное через firewall.
Пара примеров
Для закрепления базовых вещей о маршрутизации.
Типичный домашний роутер
/ip route
add dst-address=0.0.0.0/0 gateway=10.10.10.1- Статический маршрут до 0.0.0.0/0 (default route)
- Connected маршрут на интерфейсе с провайдером
- Connected маршрут на интерфейсе с локальной сетью
Типичный домашний роутер с PPPoE
- Статический маршрут до default route, добавлен автоматически т.к. это указано в свойствах подключения
- Connected маршрут для PPP соединения
- Connected маршрут на интерфейсе с локальной сетью
Типичный домашний роутер с двумя провайдерами и резервированием
/ip route
add dst-address=0.0.0.0/0 gateway=10.10.10.1 distance=1 check-gateway=ping
add dst-address=0.0.0.0/0 gateway=10.20.20.1 distance=2- Статический маршрут до default route через первого провайдера с метрикой 1 и проверкой доступности шлюза
- Статический маршрут до default route через второго провайдера с метрикой 2
- Connected маршруты
Трафик до 0.0.0.0/0 идет через 10.10.10.1, пока данный шлюз доступен, иначе переключается на 10.20.20.1
Такую схему можно считать резервированием канала, но она не лишена недостатков. Если произойдет обрыв за пределами шлюза провайдера (например внутри операторской сети), ваш роутер об этом не узнает и продолжит считать маршрут активным.
Типичный домашний роутер с двумя провайдерами, резервированием и ECMP
/ip route
add dst-address=0.0.0.0/0 gateway=10.10.10.1 check-gateway=ping
add dst-address=0.0.0.0/0 gateway=10.20.20.1 check-gateway=ping
add dst-address=0.0.0.0/0 gateway=10.10.10.1,10.20.20.1 distance=1- Статические маршруты для проверки chack gateway
- Маршрут ECMP
- Connected маршруты
Маршруты для проверки синего цвета (цвет неактивных маршрутов), но это не мешает работе check gateway. В текущей версии (6.44) RoS автоматический приоритет отдается ECMP маршруту, но лучше добавить проверочные маршруты в другие таблицы маршрутизации (опция routing-mark)
На Speedtest и прочих подобных сайтах прироста скорости не будет (ECMP делит трафик по соединениям, а не по пакетам), но p2p приложения должны загружать быстрее.
Фильтрация через Routing
/ip route
add dst-address=0.0.0.0/0 gateway=10.10.10.1
add dst-address=192.168.200.0/24 gateway=10.30.30.1 distance=1
add dst-address=192.168.200.0/24 gateway=10.10.10.1 distance=2 type=blackhole- Статический маршрут до default route
- Статический маршрут до 192.168.200.0/24 через ipip туннель
- Запрещающий статический маршрут до 192.168.200.0/24 через маршрутизатор провайдера
Вариант фильтрации при которой туннельный трафик не уйдет на маршрутизатор провайдера при отключении ipip интерфейса. Подобные схемы требуются редко, т.к. можно реализовать блокировку через firewall.
Routing Loop
Петля маршрутизации — ситуация когда пакет бегает между маршрутизаторами до истечения ttl. Обычно является следствием ошибки конфигурации, в больших сетях лечится внедрением протоколов динамической маршрутизации, в маленьких — внимательностью.
Выглядит это примерно так:
Пример (наипростейший) как получить подобный результат:
Пример с Routing loop не имеет практического применения, но он показывает что маршрутизаторы понятия не имеют о таблице маршрутизации своих соседей.
Policy Base Routing и дополнительные таблицы маршрутизации
При выборе маршрута, роутер использует только одно поле из заголовка пакета (Dst. Address) — это базовая маршрутизация. Маршрутизация на базе других условий, например адреса источника, типа трафика (ToS), балансировка без ECMP, относится к Policy Base Routing (PBR) и использует дополнительные таблицы маршрутизации.
More Specific Route является основным правилом выбора маршрута, в пределах таблицы маршрутизации.
По умолчанию все правила маршрутизации добавляются в таблицу main. Администратор может создать произвольное количество дополнительных таблиц маршрутизации и направлять пакеты в них. Правила в разных таблицах не конфликтуют между собой. Если пакет не нашел подходящего правила в указанной таблице, он уйдет в таблицу main.
Пример с распределением через Firewall:
- 192.168.100.10 -> 8.8.8.8
- Трафик от 192.168.100.10 получает метку via-isp1 в
[Prerouting|Mangle] - На этапе Routing в таблице via-isp1 производится поиск маршрута до 8.8.8.8
- Маршрут найден, трафик отправляется на шлюз 10.10.10.1
- Трафик от 192.168.100.10 получает метку via-isp1 в
- 192.168.200.20 -> 8.8.8.8
- Трафик от 192.168.200.20 получает метку via-isp2 в
[Prerouting|Mangle] - На этапе Routing в таблице via-isp2 производится поиск маршрута до 8.8.8.8
- Маршрут найден, трафик отправляется на шлюз 10.20.20.1
- Трафик от 192.168.200.20 получает метку via-isp2 в
- Если один из шлюзов (10.10.10.1 или 10.20.20.1) станет недоступным, то пакет уйдет в таблицу main и будет искать подходящий маршрут там
Проблемы терминологии
В RouterOS есть определенные проблемы с терминологией.
При работе с правилами в [IP]->[Routes] указывается таблица маршрутизации, хотя и написано что метка:
В [IP]->[Routes]->[Rule] все правильно, в условии метки в действии таблицы:
Как отправить пакет в определенную таблицу маршрутизации
RouterOS дает несколько инструментов:
- Правила в
[IP]->[Routes]->[Rules] - Маршрутные метки (
action=mark-routing) в[IP]->[Firewall]->[Mangle] - VRF
Правила [IP]->[Route]->[Rules]
Правила обрабатываются последовательно, если пакет совпал с условиями правила он не проходит дальше.
Routing Rules позволяют расширить возможности маршрутизации, опираясь не только на адрес получателя, но и адрес источника и интерфейс на который был получен пакет.
Правила состоят из условий и действия:
- Условия. Практически повторяют список признаков по которым пакет проверяется в FIB, отсутствует только ToS.
- Действия
- lookup — отправить пакет в таблицу
- lookup only in table — запереть пакет в таблице, если маршрут не будет найден пакет не уйдет в таблицу main
- drop — отбросить пакет
- unreacheable — отбросить пакет с уведомлением отправителя
В FIB трафик до локальных процессов обрабатывается в обход правил [IP]->[Route]->[Rules]:
Маркировка [IP]->[Firewall]->[Mangle]
Маршрутные метки позволяют устанавливать шлюз для пакета используя практически любые условия Firewall:
Практически, потому что не все из них имеет смысл, а некоторые могут работать нестабильно.
Маркировать пакет можно двумя способами:
- Сразу ставить routing-mark
- Сначала ставить connection-mark, потом на основе connection-mark ставить routing-mark
В статье про firewall я писал, что второй вариант предпочтительнее т.к. снижает нагрузку на cpu, в случае с маркировкой маршрутов — это не совсем так. Указанные способы маркировки не всегда являются равноценными и обычно используются для решения различных задач.
Примеры использования
Переходим к примерам использования Policy Base Routing, на них гораздо проще показать зачем все это нужно.
MultiWAN и ответный исходящий (Output) трафик
Распространенная проблема, при MultiWAN конфигурации: Mikrotik доступен из сети интернет только по «активному» провайдеру.
Роутеру не важно на какой ip пришел запрос, при генерации ответа он будет искать маршрут в таблице маршрутизации, где активен маршрут через isp1. Дальше такой пакет скорее всего будет отфильтрован по пути до получателя.
Еще один интересный момент. Если на интерфейсе ether1 настроен «простой» source nat: /ip fi nat add out-interface=ether1 action=masquerade пакет уйдет в сеть с src. address=10.10.10.100, что еще больше усугубит ситуацию.
Исправить проблему можно нескольким способами, но для любого из них потребуются дополнительные таблицы маршрутизации:
/ip route
add dst-address=0.0.0.0/0 gateway=10.10.10.1 check-gateway=ping distance=1
add dst-address=0.0.0.0/0 gateway=10.20.20.1 check-gateway=ping distance=2
add dst-address=0.0.0.0/0 gateway=10.10.10.1 routing-mark=over-isp1
add dst-address=0.0.0.0/0 gateway=10.20.20.1 routing-mark=over-isp2Использование [IP]->[Route]->[Rules]
Указываем таблицу маршрутизации которая будет использована для пакетов с указанными Source IP.
/ip route rule
add src-address=10.10.10.100/32 action=lookup-only-in-table table=over-isp1
add src-address=10.20.20.200/32 action=lookup-only-in-table table=over-isp2Можно использовать action=lookup, но для локального исходящего трафика указанный вариант полностью исключает соединения с неправильного интерфейса.
- Система генерирует ответный пакет с Src. Address: 10.20.20.200
- На этапе Routing Decision(2) происходит проверка
[IP]->[Routes]->[Rules]и пакет отправляется в таблицу маршрутизации over-isp2 - В соответствии с таблицей маршрутизации пакет должен быть отправлен на шлюз 10.20.20.1 через интерфейс ether2
Данный способ не требует рабочий Connection Tracker, в отличии от использования таблицы Mangle.
Использование [IP]->[Firewall]->[Mangle]
Соединение начинается со входящего пакета, поэтому маркируем его (action=mark-connection), для исходящих пакетов от маркированного соединения устанавливаем маршрутную метку (action=mark-routing).
/ip firewall mangle
#Маркировка входящих соединений
add chain=input in-interface=ether1 connection-state=new action=mark-connection new-connection-mark=from-isp1
add chain=input in-interface=ether2 connection-state=new action=mark-connection new-connection-mark=from-isp2
#Маркировка исходящих пакетов на основе соединений
add chain=output connection-mark=from-isp1 action=mark-routing new-routing-mark=over-isp1 passthrough=no
add chain=output connection-mark=from-isp2 action=mark-routing new-routing-mark=over-isp2 passthrough=noЕсли на одном интерфейсе настроено несколько ip, можно добавить в условие dst-address для уточнения.
- На интерфейс ether2 поступает пакет открывающий соединение. Пакет попадает в
[INPUT|Mangle]где говорится маркировать все пакеты из соединения как from-isp2 - Система генерирует ответный пакет с Src. Address: 10.20.20.200
- На этапе Routing Decision(2) пакет в соответствии с таблицей маршрутизации отправляется на шлюз 10.20.20.1 через интерфейс ether1. Можете убедиться в этом залогировав пакеты в
[OUTPUT|Filter] - На этапе
[OUTPUT|Mangle]происходит проверка на наличие метки соединения from-isp2 и пакет получает маршруткую метку over-isp2 - На этапе Routing Adjusment(3) происходит проверка на наличие маршрутной метки и отправка в соответствующую таблицу маршрутизации
- В соответствии с таблицей маршрутизации пакет должен быть отправлен на шлюз 10.20.20.1 через интерфейс ether2
MultiWAN и ответный dst-nat трафик
Пример посложнее, что делать если за роутером находится сервер (например web) в частной подсети и необходимо обеспечить доступ к нему по любому из провайдеров.
/ip firewall nat
add chain=dstnat proto=tcp dst-port=80,443 in-interface=ether1 action=dst-nat to-address=192.168.100.100
add chain=dstnat proto=tcp dst-port=80,443 in-interface=ether2 action=dst-nat to-address=192.168.100.100Суть проблемы будет та же, решение похоже на вариант с Firewall Mangle, только будут использоваться другие цепочки:
/ip firewall mangle
add chain=prerouting connection-state=new in-interface=ether1 protocol=tcp dst-port=80,443 action=mark-connection new-connection-mark=web-input-isp1
add chain=prerouting connection-state=new in-interface=ether2 protocol=tcp dst-port=80,443 action=mark-connection new-connection-mark=web-input-isp2
add chain=prerouting connection-mark=web-input-isp1 in-interface=ether3 action=mark-routing new-routing-mark=over-isp1 passthrough=no
add chain=prerouting connection-mark=web-input-isp2 in-interface=ether3 action=mark-routing new-routing-mark=over-isp2 passthrough=no
На схеме не отображен NAT, но думаю и так все понятно.
MultiWAN и исходящие соединения
Можно использовать возможности PBR для создания нескольких vpn (в примере SSTP) соединений с разных интерфейсов роутера.
Дополнительные таблицы маршрутизации:
/ip route
add dst-address=0.0.0.0/0 gateway=192.168.100.1 routing-mark=over-isp1
add dst-address=0.0.0.0/0 gateway=192.168.200.1 routing-mark=over-isp2
add dst-address=0.0.0.0/0 gateway=192.168.0.1 routing-mark=over-isp3
add dst-address=0.0.0.0/0 gateway=192.168.100.1 distance=1
add dst-address=0.0.0.0/0 gateway=192.168.200.1 distance=2
add dst-address=0.0.0.0/0 gateway=192.168.0.1 distance=3Маркировка пакетов:
/ip firewall mangle
add chain=output dst-address=10.10.10.100 proto=tcp dst-port=443 action=mark-routing new-routing-mark=over-isp1 passtrough=no
add chain=output dst-address=10.10.10.101 proto=tcp dst-port=443 action=mark-routing new-routing-mark=over-isp2 passtrough=no
add chain=output dst-address=10.10.10.102 proto=tcp dst-port=443 action=mark-routing new-routing-mark=over-isp3 passtrough=noПростые правила NAT, иначе пакет уйдет с интерфейса с неправильным Src. Address:
/ip firewall nat
add chain=srcnat out-interface=ether1 action=masquerade
add chain=srcnat out-interface=ether2 action=masquerade
add chain=srcnat out-interface=ether3 action=masqueradeРазбор:
- Роутер создает три процесса SSTP
- На этапе Routing Decision (2) для данных процессов выбирается маршрут, исходя из таблицы маршрутизации main. От этого же маршрута пакет получает Src. Address привязанный к интерфейсу ether1
- В
[Output|Mangle]пакеты от разных соединений получают разные метки - Пакеты попадают в соответствующие меткам таблицы на этапе Routing Adjusment и получает новый маршрут для отправки пакетов
- Но у пакетов все еще остается Src. Address от ether1, на этапе
[Nat|Srcnat]адрес подменяется в соответствии с интерфейсом
Интересно, что на роутере вы увидите следующую таблицу соединений:
Connection Tracker отрабатывает раньше [Mangle] и [Srcnat], поэтому все соединения идут от одного адреса, если посмотреть подробнее то в Replay Dst. Address будут адреса после NAT:
На VPN сервере (на тестовом стенде он у меня один) можно увидеть что все соединения происходят с правильных адресов:
Постой способ
Есть способ проще, можно просто указать определенный шлюз для каждого из адресов:
/ip route
add dst-address=10.10.10.100 gateway=192.168.100.1
add dst-address=10.10.10.101 gateway=192.168.200.1
add dst-address=10.10.10.102 gateway=192.168.0.1Но такие маршруты будут влиять не только на исходящий но и на транзитный трафик. Плюс, если вам не нужно чтобы трафик на vpn сервера уходил через неподходящие каналы связи, то придется добавить еще 6 правил в [IP]->[Routes]с type=blackhole. В предыдущем варианте — 3 правила в [IP]->[Route]->[Rules].
Распределение соединений пользователей по каналам связи
Простые, повседневные задачи. Опять же понадобятся дополнительные таблицы маршрутизации:
/ip route
add dst-address=0.0.0.0/0 gateway=10.10.10.1 dist=1 check-gateway=ping
add dst-address=0.0.0.0/0 gateway=10.20.20.1 dist=2 check-gateway=ping
add dst-address=0.0.0.0/0 gateway=10.10.10.1 dist=1 routing-mark=over-isp1
add dst-address=0.0.0.0/0 gateway=10.20.20.1 dist=1 routing-mark=over-isp2Используя [IP]->[Route]->[Rules]
/ip route rules
add src-address=192.168.100.0/25 action=lookup-only-in-table table=over-isp1
add src-address=192.168.100.128/25 action=lookup-only-in-table table=over-isp2Если использовать action=lookup, то при отключении одного из каналов трафик уйдет в таблицу main и пойдет по рабочему каналу. Нужно это или нет — зависит от задачи.
Используя маркировки в [IP]->[Firewall]->[Mangle]
Простой пример со списками ip адресов. В принципе можно использовать практически любые условия. Единственное предостережение layer7, даже в паре с метками соединений, может показаться что всё работает правильно, но часть трафика всеравно уйдет не туда.
/ip firewall mangle
add chain=prerouting src-address-list=users-over-isp1 dst-address-type=!local action=mark-routing new-routing-mark=over-isp1
add chain=prerouting src-address-list=users-over-isp2 dst-address-type=!local action=mark-routing new-routing-mark=over-isp2«Запереть» пользователей в одной таблице маршрутизации можно через [IP]->[Route]->[Rules]:
/ip route rules
add routing-mark=over-isp1 action=lookup-only-in-table table=over-isp1
add routing-mark=over-isp2 action=lookup-only-in-table table=over-isp2Либо через [IP]->[Firewall]->[Filter]:
/ip firewall filter
add chain=forward routing-mark=over-isp1 out-interface=!ether1 action=reject
add chain=forward routing-mark=over-isp2 out-interface=!ether2 action=rejectОтступление про dst-address-type=!local
Дополнительное условие dst-address-type=!local необходимо чтобы трафик от пользователей доходил до локальных процессов роутера (dns, winbox, ssh, …). Если к роутеру подключено несколько локальных подсетей, необходимо предусмотреть чтобы трафик между ними не уходил в интернет, например используя dst-address-table.
В примере с использованием [IP]->[Route]->[Rules] подобных исключений нет, но трафик до локальных процессов доходит. Дело в том, что попадая в FIB пакет промаркированный в [PREROUTING|Mangle] имеет маршрутную метку и уходит в таблицу маршрутизации отличную от main, где нет локального интерфейса. В случае с Routing Rules, сначала проверяется предназначен ли пакет локальному процессу и только на этапе User PBR он уходит в заданную таблицу маршрутизации.
Используя [IP]->[Firewall]->[Mangle action=route]
Данное действие работает только в [Prerouting|Mangle] и позволяет направлять трафик на указанный шлюз без использования дополнительных таблиц маршрутизации, указывая адрес шлюза напрямую:
/ip firewall mangle
add chain=prerouting src-address=192.168.100.0/25 action=route gateway=10.10.10.1
add chain=prerouting src-address=192.168.128.0/25 action=route gateway=10.20.20.1Действие route имеет более низкий приоритет чем правила маршрутизации ([IP]->[Route]->[Rules]). В случае с маршрутными метками все зависит от положения правил, если правило с action=route стоит выше чем action=mark-route, то будет использовано оно (вне зависимости от флага passtrough), иначе маркировка маршрута.
На wiki очень мало информации про данное действие и все выводы получены эксперементальным путем, в любом случае я не нашел варианты когда применение данного варианта дает приимущества перед другими.
Динамическая балансировка на основе PPC
Per Connection Classificator — является более гибким аналогом ECMP. В отличии от ECMP делит трафик по соединениям более строго (ECMP ничего про соединения не знает, но в паре с Routing Cache получается нечто похожее).
PCC берет указанные поля из ip заголовка, преобразует их в 32-битное значение и делит на знаменатель. Остаток от деления сравнивается с указанным остатком и если они совпадают, то применяется указанное действие. Подробнее. Звучит дико, но работает.
Пример с тремя адресами:
192.168.100.10: 192+168+100+10 = 470 % 3 = 2
192.168.100.11: 192+168+100+11 = 471 % 3 = 0
192.168.100.12: 192+168+100+12 = 472 % 3 = 1Пример динамического распределения трафика по src.address между тремя каналами:
#Таблица маршрутизации
/ip route
add dst-address=0.0.0.0/0 gateway=10.10.10.1 dist=1 check-gateway=ping
add dst-address=0.0.0.0/0 gateway=10.20.20.1 dist=2 check-gateway=ping
add dst-address=0.0.0.0/0 gateway=10.30.30.1 dist=3 check-gateway=ping
add dst-address=0.0.0.0/0 gateway=10.10.10.1 dist=1 routing-mark=over-isp1
add dst-address=0.0.0.0/0 gateway=10.20.20.1 dist=1 routing-mark=over-isp2
add dst-address=0.0.0.0/0 gateway=10.30.30.1 dist=1 routing-mark=over-isp3
#Маркировка соединений и маршрутов
/ip firewall mangle
add chain=prerouting in-interface=br-lan dst-address-type=!local connection-state=new per-connection-classifier=src-address:3/0 action=mark-connection new-connection-mark=conn-over-isp1
add chain=prerouting in-interface=br-lan dst-address-type=!local connection-state=new per-connection-classifier=src-address:3/1 action=mark-connection new-connection-mark=conn-over-isp2
add chain=prerouting in-interface=br-lan dst-address-type=!local connection-state=new per-connection-classifier=src-address:3/2 action=mark-connection new-connection-mark=conn-over-isp3
add chain=prerouting in-interface=br-lan connection-mark=conn-over-isp1 action=mark-routing new-routing-mark=over-isp1
add chain=prerouting in-interface=br-lan connection-mark=conn-over-isp2 action=mark-routing new-routing-mark=over-isp2
add chain=prerouting in-interface=br-lan connection-mark=conn-over-isp3 action=mark-routing new-routing-mark=over-isp3При маркировке маршрутов есть дополнительное условие: in-interface=br-lan, без него под action=mark-routing попадет ответный трафик из интернета и в соответствии с таблицами маршрутизации уйдет обратно к провайдеру.
Переключение каналов связи
Check ping — хороший инструмент, но он проверяет связь только с ближайшим IP пиром, сети провайдеров обычно состоят из большого числа маршрутизаторов и обрыв связи может произойти за пределами ближайшего пира, а дальше идут магистральные операторы связи у которых тоже могут случаться проблемы, в общем check ping не всегда показывает актуальную информацию о доступе в глобальную сеть.
Если у провайдеров и крупных корпораций есть протокол динамической маршрутизации BGP, то домашним и офисным пользователем приходится самостоятельно придумывать как проверять доступ в интернет через определенный канал связи.
Обычно используются скрипты, которые через определенный канал связи проверяют доступность ip адреса в сети интернет, при этом выбирается что то надежное, например google dns: 8.8.8.8. 8.8.4.4. Но в сообществе Mikrotik для этого приспособили более интересный инструмент.
Пара слов про рекурсивную маршрутизацию
Рекурсивная маршрутизация необходима при построении Multihop BGP пиринга и в статью про основы статической маршрутизации попала только за счет ушлых пользователей MikroTik, которые придумали как использовать рекурсивный маршруты в паре с check gateway для переключение каналов связи без дополнительных скриптов.
Пришло время в общих чертах разобраться с опциями scope/target scope и каким образом маршрут привязывается к интерфейсу:
- Маршрут ищет интерфейс для отправки пакета исходя из своего значения scope и всех записей в таблице main с меньшими или равными значениями target scope
- Из найденных интерфейсов выбирается тот, через который можно отправить пакет указанному шлюзу
- Интерфейс найденной connected записи выбирается для отправки пакета на шлюз
При наличии рекурсивного маршрута происходит все тоже самое, но в два этапа:
- 1-3 К connected маршрутам добавляется еще один, через который можно достичь указанного шлюза
- 4-6 Поиск маршрута connected маршрута для «промежуточного» шлюза
Все манипуляции с рекурсивным поиском происходят в RIB, а в FIB передается только итоговый результат: 0.0.0.0/0 via 10.10.10.1 on ether1.
Пример использования рекурсивной маршрутизации для переключения маршрутов
Конфигурация:
/ip route
add dst-address=0.0.0.0/0 gateway=8.8.8.8 check-gateway=ping distance=1 target-scope=10
add dst-address=8.8.8.8 gateway=10.10.10.1 scope=10
add dst-address=0.0.0.0/0 gateway=10.20.20.1 distance=2Можно проверить, что пакеты будут отправляться на 10.10.10.1:
Check gateway ничего не знает про рекурсивную маршрутизацию и просто отправляет ping’и на адрес 8.8.8.8, который (исходя из таблицы main) доступен через шлюз 10.10.10.1.
Если происходит потеря связи между 10.10.10.1 и 8.8.8.8, то происходит отключение маршрута, но пакеты (включая проверочные ping) до 8.8.8.8 продолжают идти через 10.10.10.1:
Если происходит потеря линка на ether1, то получается неприятная ситуация, когда пакеты до 8.8.8.8 пойдут через второго провайдера:
Это проблема, если вы используете NetWatch для запуска скриптов при недоступности 8.8.8.8. При обрыве линка NetWatch просто отработает по резервному каналу связи и будет считать что все нормально. Решается добавлением дополнительного фильтрующего маршрута:
/ip route
add dst-address=8.8.8.8 gateway=10.20.20.1 distance=100 type=blackhole
На хабре есть статья, где ситуация с NetWatch рассмотрена более детально.
И да, при использовании подобного резервирования адрес 8.8.8.8 будет жестко привязан к одному из провайдеров, соответственно выбирать его в качестве источника dns не самая хорошая идея.
Пара слов про Virtual Routing and Forwarding (VRF)
Технология VRF предназначена для создания нескольких виртуальных маршрутизаторов внутри одного физического, данная технология широко применяется у операторов связи (обычно в связке с MPLS) для предоставления услуги L3VPN клиентам с пересекающимися адресами подсетей:
Но VRF в Mikrotik организован на базе таблиц маршрутизации и имеет ряд недостатков, например локальные ip адреса роутера доступны из всех VRF, подробнее можно почитать по ссылке.
Пример конфигурации vrf:
/ip route vrf
add interfaces=ether1 routing-mark=vrf1
add interfaces=ether2 routing-mark=vrf2
/ip address
add address=192.168.100.1/24 interface=ether1 network=192.168.100.0
add address=192.168.200.1/24 interface=ether2 network=192.168.200.0С устройства подключенного к ether2 видим, что проходит ping до адреса роутера из другого vrf (и это проблема), при этом ping в интернет не уходит:
Для доступа в интернет необходимо прописать дополнительный маршрут обращающийся к таблице main (в терминологии vrf это называется route leaking):
/ip route
add distance=1 gateway=172.17.0.1@main routing-mark=vrf1
add distance=1 gateway=172.17.0.1%wlan1 routing-mark=vrf2Тут показано два способа route leaking: используюя таблицу маршрутизации: 172.17.0.1@main и используя имя интерфейса: 172.17.0.1%wlan1.
И настроить маркировку для ответного трафика в [PREROUTING|Mangle]:
/ip firewall mangle
add chain=prerouting in-interface=ether1 action=mark-connection new-connection-mark=from-vrf1 passthrough=no
add chain=prerouting connection-mark=from-vrf1 routing-mark=!vrf1 action=mark-routing new-routing-mark=vrf1 passthrough=no
add chain=prerouting in-interface=ether2 action=mark-connection new-connection-mark=from-vrf2 passthrough=no
add chain=prerouting connection-mark=from-vrf2 routing-mark=!vrf1 action=mark-routing new-routing-mark=vrf2 passthrough=no
Подсети с одинаковой адресацией
Организация доступа до подсетей с одинаковой адресацией на одном роутере используя VRF и netmap:
Базовая конфигурация:
/ip route vrf
add interfaces=ether1 routing-mark=vrf1
add interfaces=ether2 routing-mark=vrf2
/ip address
add address=192.168.100.1/24 interface=ether1 network=192.168.100.0
add address=192.168.100.1/24 interface=ether2 network=192.168.100.0
add address=192.168.0.1/24 interface=ether3 network=192.168.0.0Правила firewall:
#Маркируем пакеты для отправки в правильную таблицу маршрутизации
/ip firewall mangle
add chain=prerouting dst-address=192.168.101.0/24 in-interface=ether3 action=mark-routing new-routing-mark=vrf1 passthrough=no
add chain=prerouting dst-address=192.168.102.0/24 in-interface=ether3 action=mark-routing new-routing-mark=vrf2 passthrough=no
#Средствами netmap заменяем адреса "эфимерных" подсетей на реальные подсети
/ip firewall nat
add chain=dstnat dst-address=192.168.101.0/24 in-interface=ether3 action=netmap to-addresses=192.168.100.0/24
add chain=dstnat dst-address=192.168.102.0/24 in-interface=ether3 action=netmap to-addresses=192.168.100.0/24Правила маршрутизации для возвратного трафика:
#Указание имени интерфейса тоже может считаться route leaking, но по сути тут создается аналог connected маршрута
/ip route
add distance=1 dst-address=192.168.0.0/24 gateway=ether3 routing-mark=vrf1
add distance=1 dst-address=192.168.0.0/24 gateway=ether3 routing-mark=vrf2Добавление маршрутов полученных по dhcp в заданную таблицу маршрутизации
VRF может быть интересен, если необходимо автоматически добавить динамический маршрут (например от dhcp client) в определенную таблицу маршрутизации.
Добавление интерфейса в vrf:
/ip route vrf
add interface=ether1 routing-mark=over-isp1Правила для отправки трафика (исходящего и транзитного) через таблицу over-isp1:
/ip firewall mangle
add chain=output out-interface=!br-lan action=mark-routing new-routing-mark=over-isp1 passthrough=no
add chain=prerouting in-interface=br-lan dst-address-type=!local action=mark-routing new-routing-mark=over-isp1 passthrough=noДополнительный, фейковый маршрут для работы исходящей маршрутизции:
/interface bridge
add name=bare
/ip route
add dst-address=0.0.0.0/0 gateway=bareЭтот маршрут необходим только чтобы локальные исходящие пакеты могли пройти через Routing decision (2) до [OUTPUT|Mangle] и получить маршрутную метку, если на маршрутизаторе есть другие активные маршруты до 0.0.0.0/0 в таблице main оно не требуется.
Цепочки connected-in и dynamic-in в [Routing] -> [Filters]
Фильтрация маршрутов (входящий и исходящих) — это инструмент который обычно используется вместе с протоколами динамической маршрутизации (поэтому доступен только после установки пакета routing), но во входящих фильтрах есть две интересные цепочки:
- connected-in — фильтрация connected маршрутов
- dynamic-in — фильтрация динамических маршрутов полученных PPP и DCHP
Фильтрация позволяет не только отбрасывать маршруты, но и изменять ряд опций: distance, routing-mark, comment, scope, target scope, …
Это очень точечный инструмент и если можете сделать что-то без Routing Filters (но не скриптами), то не используйте Routing Filters, не путайте себя и тех кто будет конфигурировать роутер после вас. В контексте динамической маршрутизации Routing Filters будут использоваться значительно чаще и продуктивнее.
Установка Routing Mark для динамических маршрутов
Пример с домашнего маршрутизатора. У меня настроено два VPN соединения и трафик в них должен заворачиваться в соответствием с таблицами маршрутизации. При этом я хочу что-бы маршруты создавались автоматически при активации интерфейса:
#При создании vpn подключений указываем создание default route и задаем дистанцию
/interface pptp-client
add connect-to=X.X.X.X add-default-route=yes default-route-distance=101 ...
add connect-to=Y.Y.Y.Y add-default-route=yes default-route-distance=100 ...
#Фильтрами отправляем маршруты в определенные таблицы маршрутизации на основе подсети назначения и дистанции
/routing filter
add chain=dynamic-in distance=100 prefix=0.0.0.0/0 action=passthrough set-routing-mark=over-vpn1
add chain=dynamic-in distance=101 prefix=0.0.0.0/0 action=passthrough set-routing-mark=over-vpn2Не знаю почему, наверное баг, но если создать vrf для ppp интерфейса, то маршрут до 0.0.0.0/0 всеравно попадет в таблицу main. Иначе всё было бы еще проще.
Отключение Connected маршрутов
Иногда требуется и такое:
/route filter
add chain=connected-in prefix=192.168.100.0/24 action=rejectИнструменты отладки
RouterOS предоставляет ряд средств для отладки маршрутизации:
[Tool]->[Tourch]— позволяет посмотреть пакеты на интерфейсах/ip route check— позволяет посмотреть на какой шлюз будет отправлен пакет, не работает с таблицами маршрутизации/ping routing-table=<name>и/tool traceroute routing-table=<name>— ping и трассировка используя указанную таблицу маршрутизацииaction=logв[IP]->[Firewall]— отличный инструмент, который позволяет проследить путь пакета по packet flow, данное действие доступно во всех цепочках и таблицах
Источник: habr.com
В прошлой статье мы с вами обсудили процесс маршрутизации между сетями, подключенными к интерфейсами одного единственного маршрутизатора (рекомендую ознакомиться с ней), сегодня же мы разберем, как осуществляется маршрутизация между сетями, подключенными к разным маршрутизаторам, связанным между собой. Пока что мы не будим лезть в дебри протоколов динамической маршрутизации, а разберемся, как пользоваться статической маршрутизацией. В качестве примеров, для демонстрации настройки будим использовать маршрутизаторы фирмы Cisco, доступные в Packet Tracer.
Как мы уже выяснили, если у нас всего один маршрутизатор, то нам достаточно всего лишь сконфигурировать его интерфейсы, и он сразу же будет выполнять маршрутизацию между сетями, подключенными к нему. Немного по иному обстоят дела, если в нашей сети есть несколько маршрутизаторов. Допустим, наша интерсеть сеть будет иметь следующий вид:
 |
| Объединение сетей с помощью маршрутизаторов |
Как мы и обсуждали ранее сети, подключенные к интерфейсам одного маршрутизатора, будут видеть друг друга. Так сети «левого » маршрутизатора 192.168.1.0/24, 172.20.0.0/16 и 192.168.100.0/30 будут видеть друг друга. Аналогично обстоят дела с «правым» маршрутизатором. Но вот как будут обстоять дела с взаимодействием сетей данных маршрутизаторов между собой? Например, компьютеры сети 10.0.0.0/8 не будут доступны из сети 192.168.1.0/24. Данный принцип, для всех сетей, проиллюстрирован на «жестком» рисунке ниже:
 |
| Карта доступности сетей |
Почему же некоторые сети не видят друг друга. Все очень просто, соседние маршрутизаторы не содержат записей о сетях подключенных, только к другому маршрутизатору. Например, маршрутизатор «левый» не знает о существование сети 10.0.0.0/8, подключенной к «правому» маршрутизатору.
Давайте сымитируем данную ситуацию в Cisco Packet Tracer, а заодно поищем пути ее решения. Для начала соберем в Packet Tracer следующую схему (как это сделать смотрите в предыдущей статье):
 |
| Начинаем собирать нашу сеть |
На данной схеме компьютер PC0 имеет IP адрес – 192.168.1.100, PC1 – 172.20.20.100, PC2 – 192.168.2.100, PC3 – 10.10.10.100. Интерфейсы маршрутизатора, к которым подключены компьютеры, имеют такие же адреса, как и сами компьютеры, только в четвертом октете стоит 1. Например, для интерфейса к которому подключен ПК с адресом 192.168.1.100 зададим IP адрес 192.168.1.1. В качестве шлюза по умолчанию у каждого компьютера указан интерфейс маршрутизатора, к которому он подключен. После настройке интерфейсов маршрутизаторов, сохраните их конфигурации, выполнив wr mem. Далее соединим маршрутизаторы между собой. Чтобы это сделать, нам потребуется добавить к маршрутизатору интерфейсную плату. В данном случае добавим к маршрутизатору плату NM-1FE-TX (NM – Network module, 1FE – содержит один порт FastEthernet, TX – поддерживает 10/100MBase-TX).Чтобы это сделать перейдите к окну конфигурации маршрутизатора, выключите его, щелкнув по кнопке питания изображенной на нем.
 |
| Кнопка выключения маршрутизатора в Packet Tracer |
После этого перетяните необходимую интерфейсную плату в разъем маршрутизатора.
 |
| Вставляем интерфейсную плату в маршрутизатор |
После того как карта добавлена, еще раз щелкните по тумблеру маршрутизатора, чтобы включить его. Посмотрите его интерфейсы, должен добавиться еще один – FastEthernet1/0. Повторите аналогичные действия со вторым маршрутизатором. Задайте интерфейсу FastEthernet1/0 «левого» маршрутизатора IP адрес 192.168.100.1 c с маской 255.255.255.252, а «правому маршрутизатору» 192.168.100.2 с аналогичной маской. После этого соедините интерфейсы FastEthernet1/0 этих маршрутизаторов между собой.
 |
| Маршрутизатору, соединенные между собой |
Проверим доступность компьютеров одной сети из других. Если все сделано верно, то картина доступности должна соответствовать второму рисунку данной статьи. Если вы внимательно посмотрите на данный рисунок, то заметите что на данном рисунке не все стрелки двунаправленные. С двунаправленными стрелками все понятно, если вы будите пинговать в данном направлении, то компьютеры будут отвечать вам на ваши ICMP запросы (так как происходит маршрутизация в пределах одного маршрутизатора). Намного интереснее обстоит дело с однонаправленными зелеными стрелками. Хотя пинги в данном направлении не проходят, на самом деле ICMP пакеты доходят до места назначения, но вот вернуться обратно уже не могут. Рассмотрим как это происходит на конкретном примере. Допустим, с компьютера с IP адресом 172.20.20.100 вы пытаетесь пропинговать интерфейс с IP адресом 192.168.100.2, «правого» маршрутизатора. Картина будет выглядеть следующим образом:
 |
| Интерфейс «правого» маршрутизатора не отвечает |
Попробуем отследить путь ICMP пакетов. Для этого включим дебаги (режим отладки определенных параметров) на маршрутизаторах, через которые предположительно должны пройти ICMP пакеты. Выполним команду debug ip packet, на обоих маршрутизаторах. После чего опять попытаемся пропинговать с адреса 172.20.20.100 адрес 192.168.100.2. Посмотрим, что появилось на «левом маршрутизаторе»:
IP: tableid=0, s=172.20.20.100 (FastEthernet0/1), d=192.168.100.2 (FastEthernet1/0), routed via RIB
IP: s=172.20.20.100 (FastEthernet0/1), d=192.168.100.2 (FastEthernet1/0), g=192.168.100.2, len 128, forward
Первая строка говорит о том, что на маршрутизатор прибыл пакет с адреса 172.20.20.100, направляемый на адрес 192.168.100.2. Во второй строчке говорится о том, что данный пакеты был передан дальше, ключевое слово здесь «forward».
Теперь посмотри, что творится в это же время на «правом» маршрутизаторе:
IP: tableid=0, s=172.20.20.100 (FastEthernet1/0), d=192.168.100.2 (FastEthernet1/0), routed via RIB
IP: s=172.20.20.100 (FastEthernet1/0), d=192.168.100.2 (FastEthernet1/0), len 128, rcvd 3
IP: s=192.168.100.2 (local), d=172.20.20.100 len 128, unroutable
Как видно из первых двух строчек, наш ICMP пакет все таки дошел до «правого» маршрутизатора. А что должен сделать интерфейс, на который направлялся ping? Правильно, ответить на него послав ICMP пакеты в обратном направлении с адреса 192.168.100.2 на 172.20.20.100. Вот тут то и начинаются проблемы. «Правый» маршрутизатор не имеет в своей таблице маршрутизации информации о сети 172.20.20.0/16. Шлюз по умолчанию мы еще не прописывали, поэтому маршрутизатор просто не может отослать ответы, в результате чего появляется третья строка дебага, ключевое слово в которой «unroutable».
После того как мы разобрались с тем, как в нашей сети, в данный момент, ходят пакеты. Отключим дебаги (no debug ip packet – отключает включенный ранее дебаг, show debugging – позволяет посмотреть включенные дебаги), и перейдем к настройке маршрутизации.
В нашей маленькой сети, самым простым способом настроить маршрутизацию, является добавление маршрута по умолчанию. Для того чтобы это сделать выполните на «левом» маршрутизаторе в режиме конфигурирования следующую команду:
ip route 0.0.0.0 0.0.0.0 192.168.100.2
На «правом» маршрутизаторе:
ip route 0.0.0.0 0.0.0.0 192.168.100.1
В следующих командах первые 4 цифры обозначают IP адрес сети назначения, следующие 4 цифры обозначают её маску, а последние 4 цифры – это IP адрес интерфейса, на который необходимо передать пакеты, чтобы попасть в данную сеть. Если мы указываем в качестве адреса сети 0.0.0.0 с маской 0.0.0.0, то данный маршрут становится маршрутом по умолчанию, и все пакеты, адреса назначения которых, прямо не указаны в таблице маршрутизации будут отправлены на адрес, указанный в нем.
Посмотрим как это выглядит на конкретном примере. Допустим, мы хотим пропинговать с компьютера с адресом 192.168.1.100 компьютер с IP адресом 10.10.10.100. В качестве шлюза по умолчанию на компьютере с адресом 192.168.1.100 установлен адрес интерфейса маршрутизатора 192.168.1.1. Сначала компьютер будет искать в свой таблице маршрутизации (да у обычного компьютера она тоже есть) непосредственно адрес 10.10.10.100, после того как он его не найдет, он начнет искать в таблице маршрутизации маршрут к сети 10.0.0.0/8. После того, как данный маршрут так же не будет обнаружен. ICMP пакеты будут отправлены на адрес по умолчанию, то есть на интерфейс маршрутизатора с адресом 192.168.1.1. Получив пакет, маршрутизатор просмотрит адрес его назначения – 10.10.10.100 и также попытается обнаружить его в свой таблице маршрутизации. Когда это не увенчается успехом, маршрутизатор попробует найти в свой таблице маршрутизации маршрут к сети 10.0.0.0/8. Когда он не обнаружит и его, пакет будет отправлен используя, только что заданный нами, маршрут по умолчанию. И ICMP пакет будет передан на интерфейс, с адресом 192.168.100.2, «правого» маршрутизатора. Правый маршрутизатор попробует обнаружить в свой таблице маршрутизации маршрут к адресу 10.10.10.100. Когда это не увенчается успехом, «правый» маршрутизатор будет искать маршрут к сети 10.0.0.0/8. Информация о данной сети содержится в таблице маршрутизации, и маршрутизатор знает, что для того чтобы попасть в данную сеть необходимо отправить пакеты на интерфейс FastEthernet0/1, непосредственно к которому подключена данная сеть. Так как в нашем примере вся сеть 10.0.0.0/8, представляет из себя всего 1 компьютер, то пакеты сразу же попадают в место назначения, компьютер с IP адресом 10.10.10.100. При отсылке ответных ICMP пакетов, все происходит аналогичным образом, только адресом назначения уже будет являться 192.168.1.100/24.
К сожалению далеко не всегда можно обойтись указанием только маршрутов по умолчанию. В более сложных сетевых конфигурациях может потребоваться прописывать маршрут для каждой из сетей в отдельности. Давайте сразу рассмотрим как же это делается. Для этого, сначала удалим из таблицы маршрутизации все статически добавленные маршруты, используя команду no ip route xxxx(адрес сети) yyyy(маска) zzzz(адрес интерфейса). В конечном итоге таблицы маршрутизации должны содержать только информацию о непосредственно подключенных к ним сетях. Для «левого» маршрутизатора таблица будет примерно такой:
 |
| Содержимое таблицы маршрутизации |
Теперь нам необходимо добавить к каждому из маршрутизаторов маршруты к двум сетям, которые ему неизвестны (к сетям, подключенным к соседнему маршрутизатору). На «левом» маршрутизаторе выполним:
ip route 192.168.2.0 255.255.255.0 192.168.100.2
ip route 10.0.0.0 255.0.0.0 192.168.100.2
На правом маршрутизаторе выполним:
ip route 192.168.1.0 255.255.255.0 192.168.100.1
ip route 172.20.0.0 255.255.0.0 192.168.100.1
Если все сделано верно, то ваши сети должны будут взаимодействовать согласно рисунку:
 |
| Карта сети |
Как вы видите нам пришлось добавить довольно много маршрутной информации, даже в такой простой сетевой конфигурации. А представьте сколько их придется прописывать, если у вас сеть имеющая десятки маршрутизаторов… Это будет адский труд. Поэтому в больших сетях обычно используют динамическую маршрутизацию, которая кроме облегчения составления таблиц маршрутизации имеет и другие плюсы. О динамической маршрутизации, мы поговорим с вами в следующих статьях.
Сети для самых маленьких. Часть третья. Статическая маршрутизация
Время на прочтение
28 мин
Количество просмотров 543K
Мальчик сказал маме: “Я хочу кушать”. Мама отправила его к папе.
Мальчик сказал папе: “Я хочу кушать”. Папа отправил его к маме.
Мальчик сказал маме: “Я хочу кушать”. Мама отправила его к папе.
И бегал так мальчик, пока в один момент не упал.
Что случилось с мальчиком? TTL кончился.
Итак, поворотный момент в истории компании “Лифт ми Ап”. Руководство понимает, что компания, производящая лифты, едущие только вверх, не выдержит борьбы на высококонкурентном рынке. Необходимо расширять бизнес. Принято решение о покупке двух заводов: в Санкт-Петербурге и Кемерово.
Нужно срочно организовывать связь до новых офисов, а у вас ещё даже локалка не заработала.
Сегодня:
1. Настраиваем маршрутизацию между вланами в нашей сети (InterVlan routing)
2. Пытаемся разобраться с процессами, происходящими в сети, и что творится с данными.
3. Планируем расширение сети (IP-адреса, вланы, таблицы коммутации)
4. Настраиваем статическую маршрутизацию и разбираемся, как она работает.
5. Используем L3-коммутатор в качестве шлюза
Содержание:
- InterVlan Routing
- Планирование расширения
- … IP-план
- Принципы маршрутизации
- Настройка
- … Москва. Арбат
- … Провайдер
- … Санкт-Петербург. Васильевский остров
- … Санкт-Петербург. Озерки
- … Кемерово. Красная горка
- Дополнительно
- Материалы выпуска
InterVlan Routing
Чуточку практики для взбадривания.
В предыдущий раз мы настроили коммутаторы нашей локальной сети. На данный момент устройства разных вланов не видят друг друга. То есть фактически ФЭО и ПТО, например, находятся в совершенно разных сетях и не связаны друг с другом. Так же и серверная сеть существует сама по себе. Надо бы исправить эту досадную неприятность.
В нашей московской сети для маршрутизации между вланами мы будем использовать роутер cisco 2811. Иными словами он будет терминировать вланы. Кадры здесь заканчивают свою жизнь: из них извлекаются IP-пакеты, а заголовки канального уровня отбрасываются.
Процесс настройки маршрутизатора очень прост:
0) Сначала закончим с коммутатором msk-arbat-dsw1. На нём нам нужно настроить транковый порт в сторону маршрутизатора, чего мы не сделали в прошлый раз.
msk-arbat-dsw1(config)#interface FastEthernet0/24
msk-arbat-dsw1(config-if)# description msk-arbat-gw1
msk-arbat-dsw1(config-if)# switchport trunk allowed vlan 2-3,101-104
msk-arbat-dsw1(config-if)# switchport mode trunk
1) Назначаем имя маршрутизатора командой hostname, а для развития хорошего тона, надо упомянуть, что лучше сразу же настроить время на устройстве. Это поможет вам корректно идентифицировать записи в логах.
Router0#clock set 12:34:56 7 august 2012
Router0# conf t
Router0(config)#hostname msk-arbat-gw1
Желательно время на сетевые устройства раздавать через NTP (любую циску можно сделать NTP-сервером, кстати)
2) Далее переходим в режим настройки интерфейса, обращённого в нашу локальную сеть и включаем его, так как по умолчанию он находится в состоянии Administratively down.
msk-arbat-gw1(config)#interface fastEthernet 0/0
msk-arbat-gw1(config-if)#no shutdown
3) Создадим виртуальный интерфейс или иначе его называют подинтерфейс или ещё сабинтерфейс (sub-interface).
msk-arbat-gw1(config)#interface fa0/0.2
msk-arbat-gw1(config-if)#description Management
Логика тут простая. Сначала указываем обычным образом физический интерфейс, к которому подключена нужная сеть, а после точки ставим некий уникальный идентификатор этого виртуального интерфейса. Для удобства, обычно номер сабинтерфейса делают аналогичным влану, который он терминирует.
4) Теперь вспомним о стандарте 802.1q, который описывает тегирование кадра меткой влана. Следующей командой вы обозначаете, что кадры, исходящие из этого виртуального интерфейса будут помечены тегом 2-го влана. А кадры, входящие на физический интерфейс FastEthernet0/0 с тегом этого влана будут приняты виртуальным интерфейсом FastEthernet0/0.2.
msk-arbat-gw1(config-if)#encapsulation dot1Q 2
5) Ну и как на обычном физическом L3-интерфейсе, определим IP-адрес. Этот адрес будет шлюзом по умолчанию (default gateway) для всех устройств в этом влане.
msk-arbat-gw1(config-if)#ip address 172.16.1.1 255.255.255.0
Аналогичным образом настроим, например, 101-й влан:
msk-arbat-gw1(config)#interface FastEthernet0/0.101
msk-arbat-gw1(config-if)#description PTO
msk-arbat-gw1(config-if)#encapsulation dot1Q 101
msk-arbat-gw1(config-if)#ip address 172.16.3.1 255.255.255.0
и теперь убедимся, что с компьютера из сети ПТО мы видим сеть управления:
Работает и отлично, настройте пока все остальные интерфейсы. Проблем с этим возникнуть не должно.
Физика и логика процесса межвланной маршрутизации
Что происходит в это время с вашими данными?
Мы рассуждали в прошлый раз, что происходит, если вы пытаетесь связаться с устройством из той же самой подсети, в которой находитесь вы.
Под той же самой подсетью мы понимаем следующее.
Например, на вашем компьютере настроено следующее:
IP: 172.16.3.2
Mask: 255.255.255.0
GW: 172.16.3.1
Все устройства, адреса которых будут находиться в диапазоне 172.16.3.1-172.16.3.254 с такой же маской, как у вас будут являться членами вашей подсети. Что происходит с данными, если вы отправляет их на устройство с адресом из этого диапазона?
Повторим это с некоторыми дополнениями.
Для отправки данных они должны быть упакованы в Ethernet-кадр, в заголовок которого должен быть вставлен MAC-адрес удалённого устройства. Но откуда его взять?
Для этого ваш компьютер рассылает широковещательный ARP-запрос. В качестве IP-адреса узла назначения в IP-пакет с этим запросом будет помещён адрес искомого хоста. Сетевая карта при инкапсуляции указывает MAC-адрес FF:FF:FF:FF:FF:FF — это значит, что кадр предназначен всем устройствам. Далее он уходит на ближайший коммутатор и копии рассылаются на все порты нашего влана (ну, кроме, конечно, порта, из которого получен кадр). Получатели видят, что запрос широковещательный и они могут оказаться искомым хостом, поэтому извлекают данные из кадра. Все те устройства, которые не обладают указанным в ARP-запросе IP-адресом, просто игнорируют запрос, а вот устройство-настоящий получатель ответит на него и вышлет первоначальному отправителю свой MAC-адрес. Отправитель (в данном случае, наш компьютер) помещает полученный MAC в свою таблицу соответствия IP и MAC адресов ака ARP-кэш. Как выглядит ARP-кэш на вашем компьютере прямо сейчас, вы можете посмотреть с помощью команды arp -a
Потом ваши полезные данные упаковываются в IP-пакет, где в качестве получателя ставится тот адрес, который вы указали в команде/приложении, затем в Ethernet-кадр, в заголовок которого помещается полученный ARP-запросом MAC-адрес. Далее кадр отправляется на коммутатор, который согласно своей таблице MAC-адресов, решает, в какой порт его переправить дальше.
Но что происходит, если вы пытаетесь достучаться до устройства в другом влане? ARP-запрос ничего не вернёт, потому что широковещательные L2 сообщения кончаются на маршрутизаторе(т.е., в пределах широковещательного L2 домена), нужная сеть находится за ним, а коммутатор не пустит кадры из одного влана в порт другого. И вот для этого нужен шлюз по умолчанию (default gateway) на вашем компьютере.
То есть, если устройство-получатель в вашей же подсети, кадр просто отправляется в порт с мак-адресом конечного получателя. Если же сообщение адресовано в любую другую подсеть, то кадр отправляется на шлюз по умолчанию, поэтому в качестве MAC-адреса получателя подставится MAC-адрес маршрутизатора.
Проследим за ходом событий.
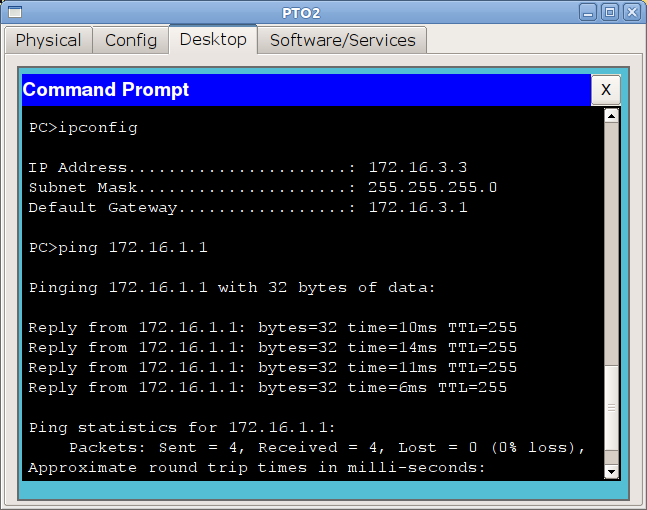
1) ПК с адресом 172.16.3.2/24 хочет отправить данные компьютеру с адресом 172.16.4.5.
Он видит, что адрес из другой подсети, следовательно, данные должны уйти на шлюз по умолчанию. Но в таком случае, ПК нужен MAC-адрес шлюза. ПК проверяет свой ARP-кэш в поисках соответствия IP-адрес шлюза — MAC-адрес и не находит нужного
2) ПК отправляет широковещательный ARP-запрос в локальную сеть. Структура ARP-запроса:
— на канальном уровне в качестве получателя — широковещательный адрес ( FF:FF:FF:FF:FF:FF), в качестве отправителя — MAC-адрес интерфейса устройства, пытающегося выяснить IP
— на сетевом — собственно ARP запрос, в нем содержится информация о том, какой IP и кем ищется.
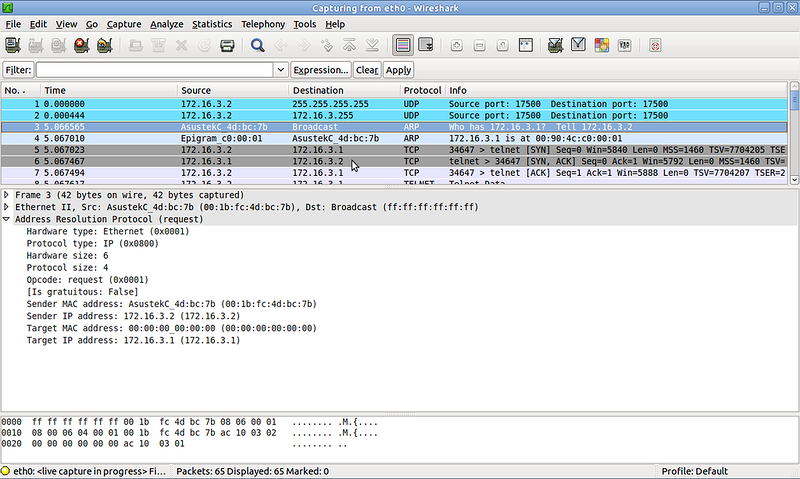
3) Коммутатор, на который попал кадр, рассылает его копии во все порты этого влана (того, которому принадлежит изначальный хост), кроме того, откуда он получен.
4) Все устройства, получив этот кадр и, видя, что он широковещательный, предполагают, что он адресован им.
5) Распаковав кадр, все хосты, кроме маршрутизатора, видят, что в ARP-запросе не их адрес. А маршрутизатор посылает unicast’овый ARP-ответ со своим MAC-адресом.
6) Изначальный хост получает ARP-ответ, теперь у него есть MAC-адрес шлюза. Он формирует пакет из тех данных, что ему нужно отправить на 172.16.4.5. В качестве MAC-адреса получателя ПК ставит адрес шлюза. При этом IP-адрес получателя в пакете остаётся 172.16.4.5
7) Кадр посылается в сеть, коммутаторы доставляют его на маршрутизатор.
 На маршрутизаторе, в соответствии с меткой влана, кадр принимается конкретным сабинтерфейсом. Данные канального уровня откидываются.
На маршрутизаторе, в соответствии с меткой влана, кадр принимается конкретным сабинтерфейсом. Данные канального уровня откидываются.
9) Из заголовка IP-пакета, рутер узнаёт адрес получателя, а из своей таблицы маршрутизации видит, что тот находится в непосредственно подключенной к нему сети на определённом сабинтерфейсе (в нашем случае FE0/0.102).
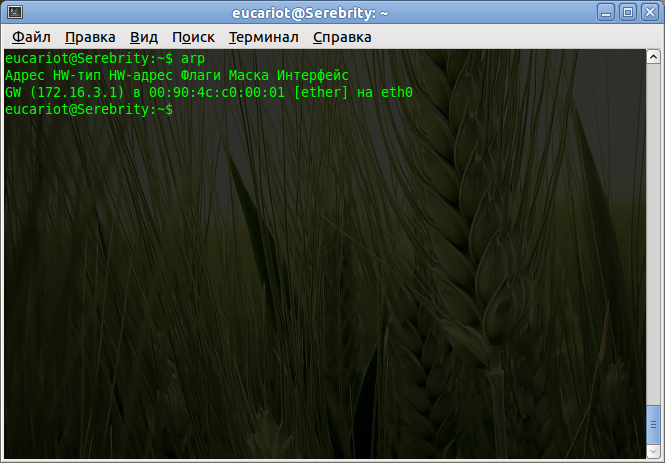
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
10) Маршрутизатор отправляет ARP-запрос с этого сабинтерфейса — узнаёт MAC-адрес получателя.
11) Изначальный IP-пакет, не изменяясь инкапсулируется в новый кадр, при этом:
— в качестве MAC-адреса источника указывается адрес интерфейса шлюза
— IP-адрес источника — адрес изначального хоста (в нашем случае 172.16.3.2)
— в качестве MAC-адреса получателя указывается адрес конечного хоста
— IP-адрес получателя — адрес конечного хоста (в нашем случае 172.16.4.5)
и отправляется в сеть с сабинтерфейса FastEthernet0/0.102, получая при этом метку 102-го влана.
12) Кадр доставляется коммутаторами до хоста-получателя.
Планирование расширения
Теперь обратимся к планированию. В нулевой части мы уже затронули эту тему, но тогда речь была только о двух офисах в Москве, теперь же сеть растёт.
Будет она вот такой:
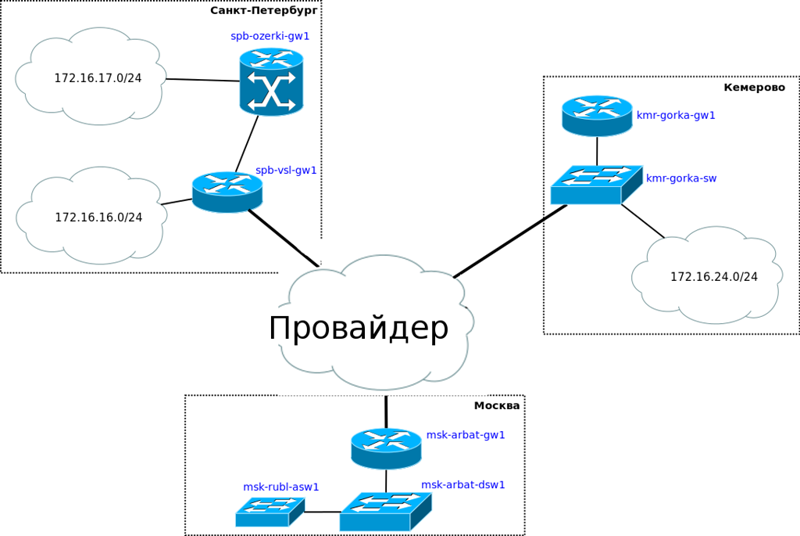
То есть прибавляются две точки в Санкт-Петербурге: небольшой офис на Васильевском острове и сам завод в Озерках — и одна в Кемерово в районе Красная горка.
Для простоты у нас будет один провайдер “Балаган Телеком”, который на выгодных условиях предоставит нам L2VPN до обеих точек.
В одном из следующих выпусков мы тему различных вариантов подключения раскроем в красках. А пока вкратце: L2VPN — это, очень грубо говоря, когда вам провайдер предоставляет влан от точки до точки (можно для простоты представить, что они включены в один коммутатор).
Следует сказать несколько слов об IP-адресации и делении на подсети.
В нулевой части мы уже затронули вопросы планирования, весьма вскользь надо сказать.
Вообще, в любой более или менее большой компании должен быть некий регламент — свод правил, следуя которому вы распределяете IP-адреса везде. Сеть у нас сейчас разрастается и разработать его очень важно.
Ну вот к примеру, скажем, что для офисов в других городах это будет так:

Это весьма упрощённый регламент, но теперь мы во всяком случае точно знаем, что у шлюза всегда будет 1-й адрес, до 12-го мы будем выдавать коммутаторам и всяким wi-fi-точкам, а все сервера будем искать в диапазоне 172.16.х.13-172.16.х.23. Разумеется, по своему вкусу вы можете уточнять регламент вплоть до адреса каждого сервера, добавлять в него правило формирования имён устройств, доменных имён, политику списков доступа и т.д.
Чем точнее вы сформулируете правила и строже будете следить за их выполнением, тем проще разбираться в структуре сети, решать проблемы, адаптироваться к ситуации
и наказывать виновных
.
Это примерно, как схема запоминания паролей: когда у вас есть некое правило их формирования, вам не нужно держать в голове несколько десятков сложнозапоминаемых паролей, вы всегда можете их вычислить.
Вот так же и тут. Я некогда работал в средних размеров холдинге и знал, что если я приеду в офис где-нибудь в забытой коровами деревне, то там точно x.y.z.1 — это циска, x.y.z.2 — дистрибьюшн-свитч прокурва, а x.y.z.101 — компьютер главного бухгалтера, с которого надо дать доступ на какой-нибудь контур-экстерн. Другой вопрос, что надо это ещё проверить, потому что местные ИТшники такого порой наворотят, что слезами омываешься сквозь смех.
Было дело парнишка решил сам управлять всем доступом в интернет (обычно это делал я на маршрутизаторе). Поставил proxy-сервер, случайно поднял на нём NAT и зарулил туда трафик локальной сети, на всех машинах прописав его в качестве шлюза по умолчанию, а потом я минут 20 разбирался, как так: у них всё работает, а мы их не видим.
IP-план
Теперь нам было бы весьма кстати составить IP-план. Будем исходить из того, что на всех трёх точках мы будем использовать стандартную сеть с маской 24 бита (255.255.255.0) Это означает, что в них может быть 254 устройства.
Почему это так? И как вообще понять все эти маски подсетей? В рамках одной статьи мы не сможем этого рассказать, иначе она получится длинная, как палуба Титаника и запутанная, как одесские катакомбы. Крайне рекомендуем очень плотно познакомиться с такими понятиями, как IP-адрес, маска подсети, их представления в двоичном виде и CIDR (Classless InterDomain Routing) самостоятельно. Мы же далее будем только аргументировать выбор конкретного размера сети. Как бы то ни было, полное понимание придёт только с практикой.
Вообще, очень неплохо эта тема раскрыта в этой статье: http://habrahabr.ru/post/129664/
В данный момент (вспомним нулевой выпуск) у нас в Москве использованы адреса 172.16.0.0-172.16.6.255. Предположим, что сеть может ещё увеличиться здесь, допустим, появится офис на Воробьёвых горах и зарезервируем ещё подсети до 172.16.15.0/24 включительно.
Все эти адреса: 172.16.0.0-172.16.15.255 — можно описать так: 172.16.0.0/20. Эта сеть (с префиксом /20) будет так называемой суперсетью, а операция объединения подсетей в суперсети называется суммированием подсетей (суммированием маршрутов, если быть точным, route summarization)
Очень наглядный IP-калькулятор. Я и сейчас им периодически пользуюсь, хотя со временем приходит интуитивное и логическое понимание соответствия между длиной маски и границами сети.
Теперь обратимся к Питеру. В данный момент в этом прекрасном городе у нас 2 точки и на каждой из них подсети /24. Допустим это будут 172.16.16.0/24 и 172.16.17.0/24. Зарезервируем адреса 172.16.18.0-172.16.23.255 для возможного расширения сети.
172.16.16.0-172.16.23.255 можно объединить в 172.16.16.0/21 — в общем-то исходя именно из этого мы и оставляем в резерв именно такой диапазон.
В Кемерово нам нет смысла оставлять такие огромные запасы /21, как в Питере (2048 адресов или 8 подсетей /24), или тем более /20, как в Москве (4096 или 16 подсетей /24). А вот 1024 адреса и 4 подсети /24, которым соответствует маска /22 вполне рационально.
Таким образом сеть 172.16.24.0/22 (адреса 172.16.24.0-172.16.27.255) будет у нас для Кемерово.
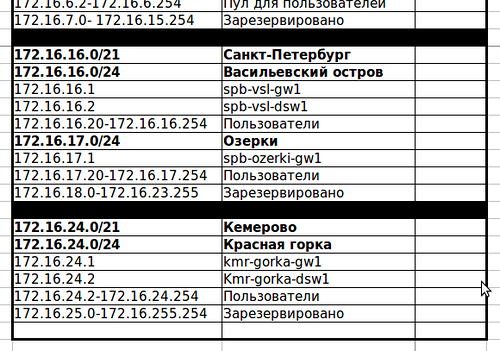
Тут надо бы заметить: делать такой запас в общем-то необязательно и то, что мы зарезервировали вполне можно использовать в любом другом месте сети. Нет табу на этот счёт. Однако в крупных сетях именно так и рекомендуется делать и связано это с количеством информации в таблицах маршрутизации.
Понимаете ли дело вот в чём: если у вас несколько подряд идущих подсетей разбросаны по разным концам сети, то каждой из них соответствует одна запись в таблице маршрутизации каждого маршрутизатора. Если при этом вы вдруг используете только статическую маршрутизацию, то это ещё колоссальный труд по настройке и отслеживанию корректности настройки.
А если же они у вас все идут подряд, то несколько маленьких подсетей вы можете суммировать в одну большую.
Поясним на примере Санкт-Петербурга. При настройке статической маршрутизации мы могли бы делать так:
ip route 172.16.16.0 255.255.255.0 172.16.2.2
ip route 172.16.17.0 255.255.255.0 172.16.2.2
ip route 172.16.18.0 255.255.255.0 172.16.2.2
……
ip route 172.16.23.0 255.255.255.0 172.16.2.2
Это 8 команд и 8 записей в таблице. Но при этом пришедший на маршрутизатор пакет в любую из сетей 172.16.16.0/21 в любом случае будет отправлен на устройство с адресом 172.16.2.2.
Вместо этого мы поступим так:
ip route 172.16.16.0 255.255.248.0 172.16.2.2
И вместо восьми возможных сравнений будет только одно.
Для современных устройств ни в плане процессорного времени ни использования памяти это уже не является существенной нагрузкой, однако такое планирование считается правилами хорошего тона и в конечном итоге вам же самим проще разобраться.
Но, положа руку на сердце, такое планирование скорее исключение, нежели правило: так или иначе фрагментация маршрутов с ростом сети неизбежна.
Теперь ещё несколько слов о “линковых” сетях. В среде сетевых администраторов так называются сети точка-точка (Point-to-Point) между двумя маршрутизаторами.
Вот опять же в примере с Питером. Два маршрутизатора (в Москве и в Петербурге) соединены друг с другом прямым линком (неважно, что у провайдера это сотня коммутаторов и маршрутизаторов — для нас это просто влан). То есть кроме вот этих 2-х устройств здесь не будет никаких других. Мы знаем это наверняка. В любом случае на интерфейсах обоих устройств (смотрящих в сторону друг друга) нужно настраивать IP-адреса. И нам точно незачем назначать на этом участке сеть /24 с 254 доступными адресами, ведь 252 в таком случае пропадут почём зря. В этом случае есть прекрасный выход — бесклассовая IP-адресация.
Почему она бесклассовая? Если вы помните, то в нулевой части мы говорили о трёх классах подсетей: А, В и С. По идее только их вы и могли использовать при планировании сети. Бесклассовая междоменная маршрутизация (CIDR) позволяет очень гибко использовать пространство IP-адресов.
Мы просто берём сеть с самой маленькой возможной маской — 30 (255.255.255.252) — это сеть на 4 адреса. Почему мы не можем взять сеть с ещё более узкой маской? Ну 32 (255.255.255.255) по понятными причинам — это вообще один единственный адрес, сеть 31 (255.255.255.254) — это уже 2 адреса, но один из них (первый) — это адрес сети, а второй (последний) — широковещательный. В итоге на адреса хостов у нас и не осталось ничего. Поэтому и берём маску 30 с 4 адресами и тогда как раз 2 адреса остаются на наши два маршрутизатора.
Вообще говоря, самой узкой маской для подсетей в cisco таки является /31. При определённых условиях их можно использовать на P-t-P-линках.
Что же касается маски /32, то такие подсети, которые суть один единственный хост используются для назначения адресов Loopback-интерфейсам.
Именно так мы и поступим. Для этого, собственно, в нулевой части мы и оставили сеть 172.16.2.0/24 — её мы будем дробить на мелкие сетки /30. Всего их получится 64 штуки, соответственно можно назначить их на 64 линка.
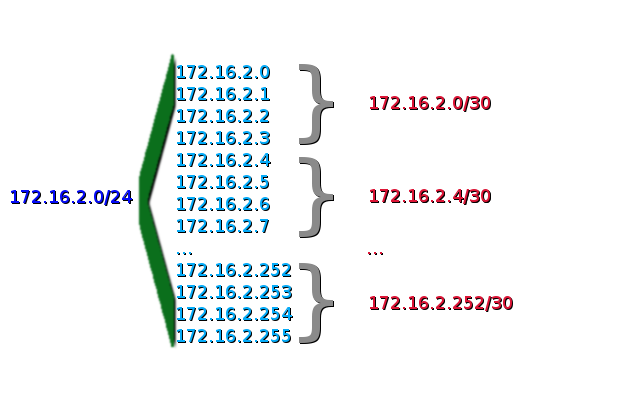
Здесь мы поступили так же, как и в предыдущем случае: сделали небольшой резерв для Питера, и резерв для Кемерово. Вообще резерв — это всегда очень хорошо о чём бы мы ни говорили. 
Принципы маршрутизации
Перед началом настройки стоит определиться с тем, для чего нужна маршрутизация вообще.
Рассмотрим такую сеть:
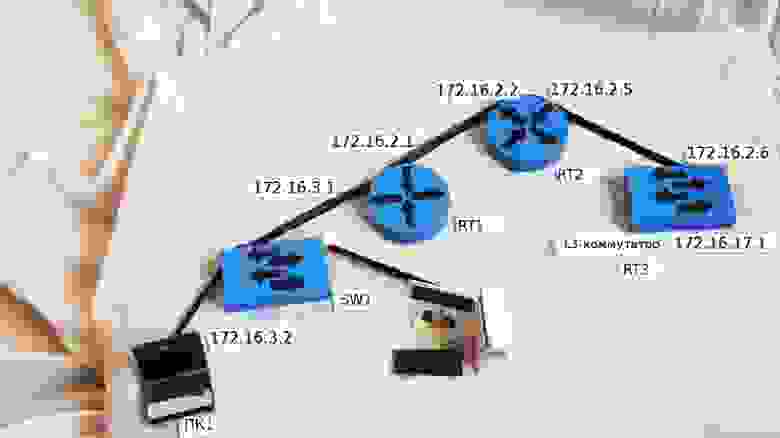
Вот к примеру с компьютера ПК1 — 172.16.3.2 я хочу подключиться по telnet к L3-коммутатору с адресом 172.16.17.1.
Как мой компьютер узнает что делать? Куда слать данные?
1) Как вы уже знаете, если адрес получателя из другой подсети, то данные нужно отправлять на шлюз по умолчанию.
2) По уже известной вам схеме компьютер с помощью ARP-запроса добывает MAC-адрес маршрутизатора.
3) Далее он формирует кадр с инкапсулированным в него пакетом и отсылает его в порт. После того, как кадр отправлен, компьютеру уже по барабану, что происходит с ним дальше.
4) А сам кадр при этом попадает сначала на коммутатор, где решается его судьба согласно таблице MAC-адресов. А потом достигает маршрутизатора RT1.
5) Поскольку маршрутизатор ограничивает широковещательный домен — здесь жизнь этого кадра и заканчивается. Циска просто откидывает заголовок канального уровня — он уже не пригодится — извлекает из него IP-пакет.
6) Теперь маршрутизатор должен принять решение, что с ним делать дальше. Разумеется, отправить его на какой-то свой интерфейс. Но на какой?
Для этого существует таблица маршрутизации, которая есть на любом рутере. Выяснить, что у нас в данный момент находится в таблице маршрутизации, можно с помощью команды show ip route:
172.16.0.0/16 is variably subnetted, 10 subnets, 3 masks
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.17.0/24 [1/0] via 172.16.2.2
Каждая строка в ней — это способ добраться до той или иной сети.
Вот к примеру, если пакет адресован в сеть 172.16.17.0/24, то данные нужно отправить на устройство с адресом 172.16.2.2.
Таблица маршрутизации формируется из:
— непосредственно подключенных сетей (directly connected) — это сети, которые начинаются непосредственно на нём. В примере 172.16.3.0/24 и 172.16.2.0/30. В таблице они обозначаются буквой C
— статический маршруты — это те, которые вы прописали вручную командой ip route. Обозначаются буквой S
— маршруты, полученные с помощью протоколов динамической маршрутизации (OSPF, EIGRP, RIP и других).
7) Итак, данные в сеть 172.16.17.0 (а мы хотим подключиться к устройству 172.16.17.1) должны быть отправлены на следующий хоп — следующий прыжок, которым является маршрутизатор 172.16.2.2. Причём из таблицы маршрутизации видно, что находится следующий хоп за интерфейсом FE0/1.4 (подсеть 172.16.2.0/30).
8)Если в ARP-кэше циски нет MAC-адреса, то надо снова выполнить ARP-запрос, чтобы узнать MAC-адрес устройства с IP-адресом 172.16.2.2. RT1 посылает широковещательный кадр с порта FE0/1.4. В этом широковещательном домене у нас два устройства, и соответственно только один получатель. RT2 получает ARP-запрос, отбрасывает заголовок Ethernet и, понимая из данных протокола ARP, что искомый адрес принадлежит ему отправляет ARP-ответ со своим MAC-адресом.
9) Изначальный IP-пакет, пришедший на RT1 не меняется, он инкапсулируется в совершенно новый кадр и отправляется в порт FE0/1.4, получая при этом метку 4-го влана.
10) Полностью аналогичные действия происходят на следующем маршрутизаторе. И на следующем и следующем (если бы они были), пока пакет не дойдёт до последнего, к которому и подключена нужная сеть.
11) Последний маршрутизатор видит, что искомый адрес принадлежит ему самому, а извлекая данные транспортного уровня, понимает, что это телнет и передаёт все данные верхним уровням.
Так вот и путешествуют данные с одного хопа на другой и ни один маршрутизатор представления не имеет о дальнейшей судьбе пакета. Более того, он даже не знает есть ли там действительно эта сеть — он просто доверяет своей таблице маршрутизации.
Настройка
Каким образом мы организуем каналы связи? Как мы уже сказали выше, в нашем офисе на Арбате есть некий провайдер Балаган-Телеком. Он обещает нам предоставить всё, что мы только захотим почти задарма. И мы заказываем у него две услуги L2VPN, то есть он отдаст нам два влана на Арбате в Москве, и по одному в Питере и Кемерово.
Вообще говоря, номера вланов вам придётся согласовывать с вашим провайдером по той простой причине, что у него они могут быть просто заняты. Поэтому вполне возможно, что у вас будет влан, например, 2912 или 754. Но предположим, что нам повезло, и мы вольны сами выбирать номер.
Москва. Арбат
На циске в Москве у нас два интерфейса, к одному — FE0/0 — уже подключена наша локальная сеть, а второй (FE0/1)мы будем использовать для выхода в интернет и для подключения удалённых офисов.
Как и в самом начале создадим саб-интерфейсы. Выделим для Санкт-Петербурга и Кемерова 4 и 5-й вланы соответственно. IP-адреса берём из нового IP-плана.
msk-arbat-gw1(config)#interface FastEthernet 0/1.4
msk-arbat-gw1(config-subif)#description Saint-Petersburg
msk-arbat-gw1(config-subif)#encapsulation dot1Q 4
msk-arbat-gw1(config-subif)#ip address 172.16.2.1 255.255.255.252msk-arbat-gw1(config)#interface FastEthernet 0/1.5
msk-arbat-gw1(config-subif)#description Kemerovo
msk-arbat-gw1(config-subif)#encapsulation dot1Q 5
msk-arbat-gw1(config-subif)#ip address 172.16.2.17 255.255.255.252
Провайдер
Разумеется, мы не будем строить всю сеть провайдера. Вместо этого просто поставим коммутатор, ведь по сути сеть провайдера с нашей точки зрения будет одним огромным абстрактным коммутатором.
Тут всё просто: принимаем транком линк с Арбата в один порт и с двух других портов отдаём их на удалённые узлы. Ещё раз хотим
подчеркнуть
, что все эти 3 порта не принадлежат одному коммутатору — они разнесены на сотни километров, между ними сложная MPLS-сеть с кучей коммутаторов.
Настраиваем “эмулятор провайдера”:
Switch(config)#vlan 4
Switch(config-vlan)#vlan 5
Switch(config)#interface fa0/1
Switch(config-if)#switchport mode trunk
Switch(config-if)#switchport trunk allowed vlan 4-5
Switch(config-if)#exit
Switch(config)#int fa0/2
Switch(config-if)#switchport trunk allowed vlan 4
Switch(config-if)#int fa0/3
Switch(config-if)#switchport trunk allowed vlan 5
Санкт-Петербург. Васильевский остров
Теперь обратимся к нашему spb-vsl-gw1. Тут у нас тоже 2 порта, но решим вопрос нехватки портов иначе: добавим сюда плату. Плата с двумя FastEthernet-портам и двумя слотами для WIC вполне подойдёт.
Пусть встроенные порты будут для локальной сети, а порты на дополнительной плате мы используем для аплинка и связи с Озерками.
Здесь вы можете увидеть отличие в нумерации портов и понять их смысл.
FastEthernet — это тип порта (Ethernet, Fastethernet, GigabitEthernet, POS, Serial или другие)
x/y/z.w=Slot/Sub-slot/Interface.Sub-interface.
Каким образом здесь вам провайдер будет отдавать канал — транком или аксесом, вы решаете сообща. Как правило, для него не составит проблем ни один из вариантов.
Но мы уже настроили транк, поэтому соответствующим образом настраиваем порт на циске:
spb-vsl-gw1(config)interface FastEthernet1/0.4
spb-vsl-gw1(config-if)description Moscow
spb-vsl-gw1(config-if)encapsulation dot1Q 4
spb-vsl-gw1(config-if)ip address 172.16.2.2 255.255.255.252
Добавим ещё локальную сеть:
spb-vsl-gw1(config)#int fa0/0
spb-vsl-gw1(config-if)#description LAN
spb-vsl-gw1(config-if)#ip address 172.16.16.1 255.255.255.0
Вернёмся в Москву. С msk-arbat-gw1 мы можем увидеть адрес 172.16.2.2:
msk-arbat-gw1#ping 172.16.2.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 2/7/13 ms
Но так же не видим 172.16.16.1:
msk-arbat-gw1#ping 172.16.16.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.16.1, timeout is 2 seconds:
…
Success rate is 0 percent (0/5)
Опять же, потому что маршрутизатор не знает, куда слать пакет:
msk-arbat-gw1#sh ip route
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 8 subnets, 2 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
Исправим это недоразумение:
msk-arbat-gw1(config)#ip route 172.16.16.0 255.255.255.0 172.16.2.2
msk-arbat-gw1#sh ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D — EIGRP, EX — EIGRP external, O — OSPF, IA — OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static routeGateway of last resort is not set
172.16.0.0/16 is variably subnetted, 9 subnets, 2 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/24 [1/0] via 172.16.2.2
Теперь пинг появляется:
msk-arbat-gw1#ping 172.16.16.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.16.1, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/10/24 ms
Вот, казалось бы оно — счастье, но проверим связь с компьютера:
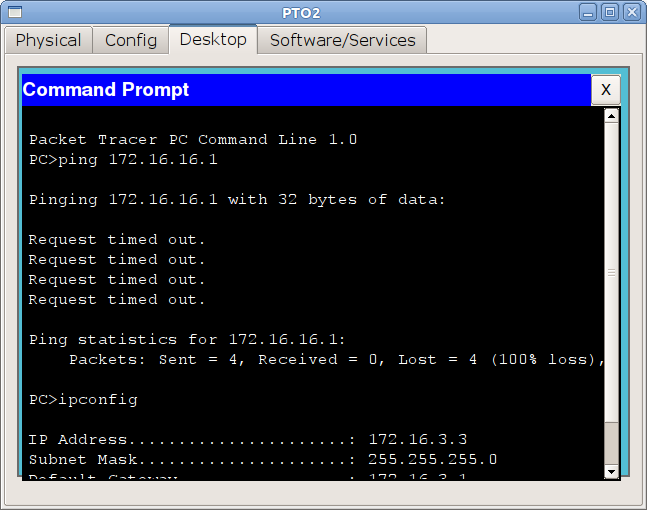
В чём дело?!
Компьютер знает, куда отправлять пакет — на свой шлюз 172.16.3.1, маршрутизатор тоже знает — на хост 172.16.2.2. Пакет уходит туда, принимается spb-vsl-gw1, который знает, что пингуемый адрес 172.16.16.1 принадлежит ему. А обратно нужно отправить пакет на адрес 172.16.3.3, но в сеть 172.16.3.0 у него нет маршрута. А пакеты, сеть назначения которых неизвестна, просто дропятся — отбрасываются.
spb-vsl-gw1#sh ip route
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 2 subnets, 2 masks
C 172.16.2.0/30 is directly connected, FastEthernet1/0.4
C 172.16.16.0/24 is directly connected, FastEthernet0/0
Но, почему же, спросите вы, с msk-arbat-gw1 до 172.16.16.1 пинг был? Какая разница 172.16.3.1 или 172.16.3.2? Всё просто.
Из таблицы маршрутизации всем видно, что следующий хоп — 172.16.2.2, при этом адрес из 172.16.2.1 принадлежит интерфейсу этого маршрутизатора, поэтому он и ставится в заголовок в качестве IP-адреса отправителя, а не 172.16.3.1. Пакет отправляется на spb-vsl-gw1, тот его принимает, передаёт данные приложению пинг, которое формирует echo-reply. Ответ инкапсулируется в IP-пакет, где в качестве адреса получателя фигурирует 172.16.2.1, а 172.16.2.0/30 — непосредственно подключенная к spb-vsl-gw1 сеть, поэтому без проблем пакет доставляется по назначению. То етсь в сеть 172.16.2.0/30 маршрут известен, а в 172.16.3.0/24 нет.
Для решения этой проблемы мы можем прописать на spb-vsl-gw1 маршрут в сеть 172.16.3.0, но тогда придётся прописывать и для всех других сетей. Для всех сетей в Москве, потом в Кемерово, потом в других городах — очень большой объём настройки.
И тут стоить заметить, что по сути у нас только один выход в мир — через Москву. Узел в Озерках — тупиковый, а других нет. То есть в основном все данные будут уходить в Москву, где большая часть подсетей и будет выход в интернет.
Чем нам это может помочь? Есть такое понятие — маршрут по умолчанию, ещё он носит романтическое название шлюз — последней надежды. И второму есть объяснение. Когда маршрутизатор решает, куда отправить пакет, он просматривает всё таблицу маршрутизации и, если не находит нужного маршрута, пакет отбрасывается — это если у вас не настроен шлюз последней надежды, если же настроен, то сиротливые пакеты отправляются именно туда — просто не глядя, предоставляя право уже следующему хопу решать их дальнейшую судьбу. То есть если некуда отправить, то последняя надежда — маршрут по умолчанию.
Настраивается он так:
spb-vsl-gw1(config)#ip route 0.0.0.0 0.0.0.0 172.16.2.1
И теперь тадааам:
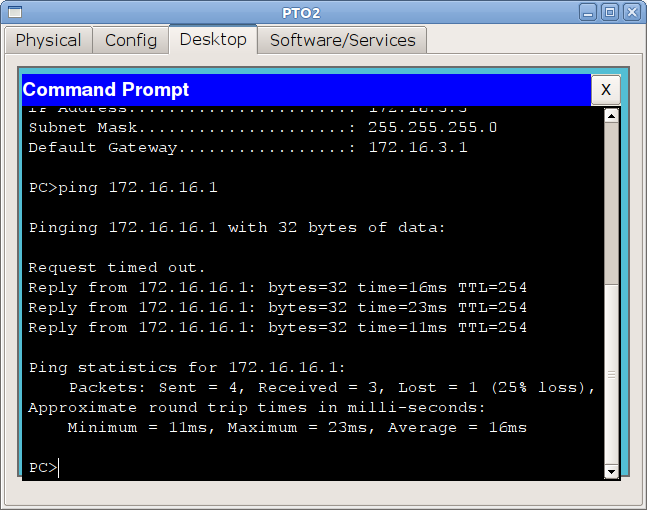
В случае таких тупиковых областей довольно часто применяется именно шлюз последней надежды, чтобы уменьшить количество маршрутов в таблице и сложность настройки.
Санкт-Петербург. Озерки
Теперь озаботимся Озерками. Здесь мы поставим L3-коммутатор. Допустим, связаны они у нас будут арендованным у провайдера волокном (конечно, это идеализированная ситуация для маленькой компании, но можно же помечтать).
Использование коммутаторов третьего уровня весьма удобно в некоторых случаях. Во-первых, интервлан роутинг в этом случае делается аппаратно и не нагружает процессор, в отличие от маршрутизатора. Кроме того, один L3-коммутатор обойдётся вам значительно дешевле, чем L2-коммутатор и маршрутизатор по отдельности. Правда, при этом вы лишаетесь ряда функций, естественно. Поэтому при выборе решения будьте аккуратны.
Настроим маршрутизатор на Васильевском острове, согласно плану:
spb-vsl-gw1(config)interface fa1/1
spb-vsl-gw1(config-if)#description Ozerki
spb-vsl-gw1(config-if)#ip address 172.16.2.5 255.255.255.252
Поскольку мы уже запланировали сеть для Озерков 172.16.17.0/24, то можем сразу прописать туда маршрут:
spb-vsl-gw1(config)#ip route 172.16.17.0 255.255.255.0 172.16.2.6
В качестве некст хопа ставим адрес, который мы выделили для линковой сети на Озерках — 172.16.2.6
Теперь перенесёмся в сами Озерки:
Подключим кабель в уже настроенный порт fa1/1 на стороне Васильевского острова и в 24-й порт 3560 в Озерках.
По умолчанию все порты L3-коммутатора работают в режиме L2, то есть это обычные “свитчёвые” порты, на которых мы можем настроить вланы. Но любой из них мы можем перевести в L3-режим, сделав портом маршрутизатора. Тогда на нём мы сможем настроить IP-адрес:
Switch(config)#hostname spb-ozerki-gw1
spb-ozerki-gw1(config)#interface fa0/24
spb-ozerki-gw1(config-if)#no switchport
spb-ozerki-gw1(config-if)#ip address 172.16.2.6 255.255.255.252
Проверяем связь:
spb-ozerki-gw1#ping 172.16.2.5
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.2.5, timeout is 2 seconds:
.!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 1/18/61 ms
Настроим ещё локальную сеть. Напомним, что Cisco и другие производители и не только производители не рекомендуют использовать 1-й влан, поэтому, мы воспользуемся 2-м:
spb-ozerki-gw1(config)#vlan 2
spb-ozerki-gw1(config-vlan)#name LAN
spb-ozerki-gw1(config-vlan)#exit
spb-ozerki-gw1(config)#interface vlan 2
spb-ozerki-gw1(config-if)#description LAN
spb-ozerki-gw1(config-if)#ip address 172.16.17.1 255.255.255.0
spb-ozerki-gw1(config)#interface fastEthernet 0/1
spb-ozerki-gw1(config-if)#description Pupkin
spb-ozerki-gw1(config-if)#switchport mode access
spb-ozerki-gw1(config-if)#switchport access vlan 2
После этого все устройства во втором влане будут иметь шлюзом 172.16.17.1
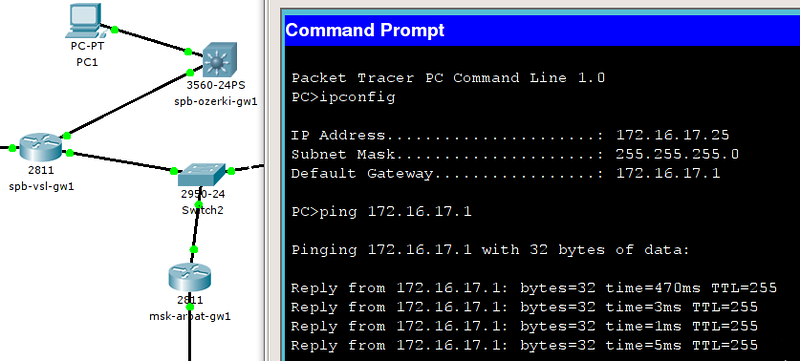
Чтобы коммутатор превратился в почти полноценный маршрутизатор, надо дать ещё одну команду:
spb-ozerki-gw1(config)#ip routing
Таким образом мы включим возможность маршрутизации.
Никаких других маршрутов, кроме как по умолчанию нам тут не надо:
spb-ozerki-gw1(config)#ip route 0.0.0.0 0.0.0.0 172.16.2.5
Связь до spb-vsl-gw1 есть:
spb-ozerki-gw1#ping 172.16.16.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.16.1, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 3/50/234 ms
А до Москвы нет:
spb-ozerki-gw1#ping 172.16.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.3.1, timeout is 2 seconds:
…
Success rate is 0 percent (0/5)
Опять же дело в отсутствии маршрута. Вообще удобный инструмент для нахождения примерного места расположения проблемы traceroute:
spb-ozerki-gw1#traceroute 172.16.3.1
Type escape sequence to abort.
Tracing the route to 172.16.3.11 172.16.2.5 4 msec 2 msec 5 msec
2 * * *
3 * * *
4 *
Как видите, что от spb-vsl-gw1 ответ приходит, а дальше глухо. Это означает, как правило, что или на хопе с адресом 172.16.2.5 не прописан маршрут в нужную сеть (вспоминаем, что у нас настроен там маршрут по умолчанию, которого достаточно) или на следующем нету маршрута обратно:
msk-arbat-gw1#sh ip rou
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 9 subnets, 2 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/24 [1/0] via 172.16.2.2
Действительно маршрута в подсеть 172.16.17.0/24 нет. Мы можем прописать его, вы это уже умеете, а можем вспомнить, что целую подсеть 172.16.16.0/21 мы выделили под Питер, поэтому вместо того, чтобы по отдельности добавлять маршрут в каждую новую сеть, мы пропишем агрегированный маршрут:
msk-arbat-gw1(config)#no ip route 172.16.16.0 255.255.255.0 172.16.2.2
msk-arbat-gw1(config)#ip route 172.16.16.0 255.255.248.0 172.16.2.2
Проверяем:
msk-arbat-gw1#ping 172.16.17.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.17.1, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 4/10/18 ms
Но странной неожиданностью для вас может стать то, что с spb-ozerki-gw1 вы не увидите Москву по-прежнему:
spb-ozerki-gw1#ping 172.16.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.3.1, timeout is 2 seconds:
…
Success rate is 0 percent (0/5)
Но при этом, если в качестве адреса-источника мы укажем 172.16.17.1:
spb-ozerki-gw1#ping
Protocol [ip]:
Target IP address: 172.16.3.1
Repeat count [5]:
Datagram size [100]:
Timeout in seconds [2]:
Extended commands [n]: y
Source address or interface: ping172.16.17.1
% Invalid source
Source address or interface: 172.16.17.1
Type of service [0]:
Set DF bit in IP header? [no]:
Validate reply data? [no]:
Data pattern [0xABCD]:
Loose, Strict, Record, Timestamp, Verbose[none]:
Sweep range of sizes [n]:
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.3.1, timeout is 2 seconds:
Packet sent with a source address of 172.16.17.1
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 5/9/14 ms
И даже с компьютера 172.16.17.26 связь есть:
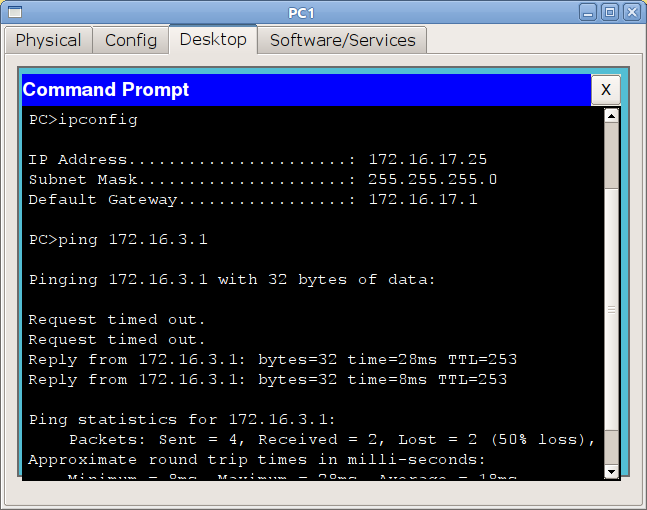
Как же так? Ответ, вы не поверите, так же прост — проблемы с маршрутизацией.
Дело в том, что msk-arbat-gw1 о подсети 172.16.17.0/24 знает, а о 172.16.2.4/30 нет. А именно адрес 172.16.2.6 — адрес ближайшего к адресату интерфейса (или интерфейса, с которого отправляется IP-пакет) подставляет по умолчанию в качестве источника. Об этом забывать не нужно.
msk-arbat-gw1(config)#ip route 172.16.2.4 255.255.255.252 172.16.2.2
spb-ozerki-gw1#ping 172.16.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.3.1, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 7/62/269 ms
Ещё интересный опыт: а что если адрес на маршрутизаторе на Васильевском острове маршрут в подсеть 172.16.3.0/24 пропишем на Озерки, а не в Москву? Ну чисто для интереса. Что произойдёт в этом случае?
spb-vsl-gw1(config)#ip route 172.16.3.0 255.255.255.0 172.16.2.6
В РТ вы этого не увидите, почему-то, но в реальной жизни получится кольцо маршрутизации. Сети 172.16.3.0/24 и 172.16.16.0/21 не будут видеть друг друга:
пакет идущий с spb-ozerki-gw1 в сеть 172.16.3.0 попадает в первую очередь на spb-vsl-gw1, где сказано: “172.16.3.0/24 ищите за 172.16.2.6”, а это снова spb-ozerki-gw1, где сказано: “172.16.3.0/24 ищите за 172.16.2.5” и так далее. Пакет будет шастать туда-обратно, пока не истечёт значение в поле TTL.
Дело в том, что при прохождении каждого маршрутизатора поле TTL в IP-заголовке, изначально имеющее значение 255, уменьшается на 1. И если вдруг окажется, что это значение равно 0, то пакет погибает, точнее маршрутизатор, увидевший это, задропит его.
Таким образом обеспечивается стабильность сети — в случае возникновения петли пакеты не будут жить бесконечно, нагружая канал до его полной утилизации.
Кстати, в Ethernet такого механизма нет и если получается петля, то коммутатор только и будет делать, что плодить широковещательные запросы, полностью забивая канал — это называется широковещательный шторм (эта проблема решается с помощью специальной технологии\протокола STP- об этом в следующем выпуске).
В общем, если вы пускаете пинг из сети 172.16.17.0 на адрес 172.16.3.1, то ваш IP-пакет будет путешествовать между двумя маршрутизаторами, пока не истечёт срок его жизни, пройдя при этом по линку между Озерками и Васильевским островом 254 раза.
Кстати, следствием из работы этого механизма является то, что не может существовать связная сеть, где между узлами больше 255 маршрутизаторов. Впрочем это и не очень актуальная потребность. Сейчас даже самый долгий трейс занимает пару-тройку десятков хопов.
Кемерово. Красная горка
Рассмотрим последний небольшой пример — маршрутизатор на палочке (router on a stick).
Название навеяно схемой подключения:
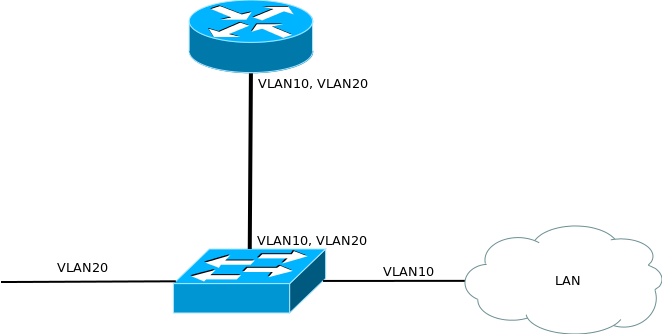
Маршрутизатор связан с коммутатором лишь одним кабелем и по разным вланам внутри него передаётся трафик и локальной сети, и внешний. Делается это, как правило, для экономии средств (на маршрутизаторе только один порт и не хочется покупать дополнительную плату).
Подключим следующим образом:
Настройка коммутатора уже не должна для вас представлять проблем. На UpLink-интерфейсе настраиваем оговоренный с провайдером 5-й влан транком:
Switch(config)#hostname kmr-gorka-sw1
kmr-gorka-sw1(config)#vlan 5
kmr-gorka-sw1(config-vlan)#name Moscowkmr-gorka-sw1(config)#int fa0/24
kmr-gorka-sw1(config-if)#description Moscow
kmr-gorka-sw1(config-if)#switchport mode trunk
kmr-gorka-sw1(config-if)#switchport trunk allowed vlan 5
В качестве влана для локальной сети выберем vlan 2 и это ничего, что он уже используется и в Москве и в Питере — если они не пересекаются и вы это можете контролировать, то номера могут совпадать. Тут каждый решает сам: вы можете везде использовать, например, 2-й влан, в качестве влана локальной сети или напротив разработать план, где номера вланов уникальны во всей сети.
kmr-gorka-sw1(config)#vlan 2
kmr-gorka-sw1(config-vlan)#name LAN
kmr-gorka-sw1(config)#int fa0/1
kmr-gorka-sw1(config-if)#description syn_generalnogo
kmr-gorka-sw1(config-if)#switchport mode access
kmr-gorka-sw1(config-if)#switchport access vlan 2
Транк в сторону маршрутизатора, где 5-ым вланом будут тегироваться кадры внешнего трафика, а 2-м — локального.
kmr-gorka-sw1(config)#int fa0/23
kmr-gorka-sw1(config-if)#description kmr-gorka-gw1
kmr-gorka-sw1(config-if)#switchport mode trunk
kmr-gorka-sw1(config-if)#switchport trunk allowed vlan 2,5
Настройка маршрутизатора:
Router(config)#hostname kmr-gorka-gw1
kmr-gorka-gw1(config)#int fa0/0.5
kmr-gorka-gw1(config-subif)#description Moscow
kmr-gorka-gw1(config-subif)#encapsulation dot1Q 5
kmr-gorka-gw1(config-subif)#ip address 172.16.2.18 255.255.255.252kmr-gorka-gw1(config)#int fa0/0
kmr-gorka-gw1(config-if)#no shkmr-gorka-gw1(config)#int fa0/0.2
kmr-gorka-gw1(config-subif)#description LAN
kmr-gorka-gw1(config-subif)#encapsulation dot1Q 2
kmr-gorka-gw1(config-subif)#ip address 172.16.24.1 255.255.255.0
Полагаем, что маршрутизацию здесь между Москвой и Кемерово вы теперь сможете настроить самостоятельно.
Дополнительно
В случае, если с маршрутизацией не всё в порядке для траблшутинга вам понадобятся две команды:
traceroute
и
show ip route
У первой бывает полезным, как вы видели, задать адрес источника. А последнюю можно применять с параметрами, например:
msk-arbat-gw1#sh ip route 172.16.17.0
Routing entry for 172.16.16.0/21
Known via «static», distance 1, metric 0
Routing Descriptor Blocks:
* 172.16.2.2
Route metric is 0, traffic share count is 1
Несмотря на то, что в таблице маршрутизации нет отдельной записи для подсети 172.16.17.0, маршрутизатор покажет вам, какой следующий хоп.
И ещё хотелось бы повторить самые важные вещи:
— Когда блок данных попадает на маршрутизатор, заголовок Ethernet полностью отбрасывается и при отправке формируется совершенно новый кадр. Но IP-пакет остаётся неизменным.
— Каждый маршрутизатор в случае статической маршрутизации принимает решение о судьбе пакета исключительно самостоятельно и не знает ничего о чужих таблицах.
— Поиск в таблице идёт НЕ до первой попавшейся подходящей записи, а до тех пор, пока не будет найдено самое точное соответствие (самая узкая маска). Например, если у вас таблица маршрутизации выглядит так:
172.16.0.0/16 is variably subnetted, 6 subnets, 3 masks
S 172.16.0.0/16 [1/0] via 172.16.2.22
C 172.16.2.20/30 is directly connected, FastEthernet0/0
C 172.16.2.24/30 is directly connected, FastEthernet0/0.2
C 172.16.2.28/30 is directly connected, FastEthernet0/0.3
S 172.16.10.0/24 [1/0] via 172.16.2.26
S 172.16.10.4/30 [1/0] via 172.16.2.30
И вы передаёте данные на 172.16.10.5, то он не пойдёт ни по маршруту через 172.16.2.22 ни через 172.16.2.26, а выберет самую узкую маску (самую длинную) /30 через 172.16.2.30.
— Если IP-адресу получателя не будет соответствовать ни одна запись в таблице маршрутизации и не настроен маршрут по умолчанию (шлюз последней надежды), пакет будет просто отброшен.
На этом первое знакомство с маршрутизацией можно закончить. Нам кажется, что читатель сам видит, сколько сложностей поджидает его здесь, может предположить, какой объём работы предстоит ему, если сеть разрастётся до нескольких десятков маршрутизаторов. Но надо сказать, что в современном мире статическая маршрутизация, не то чтобы не используется, конечно, ей есть место, но в подавляющем большинстве сетей, крупнее районного пионер-нета внедрены протоколы динамической маршрутизации. Среди них OSPF, EIGRP, IS-IS, RIP, которым мы посвятим отдельный выпуск и, скорее всего, не один. Но настройка статической маршрутизации в значительной степени поможет вашему общему пониманию маршрутизации.
В качестве самостоятельного задания попробуйте настроить маршрутизацию между Москвой и Кемерово и ответить на вопрос, почему не пингуются устройства из сети управления.
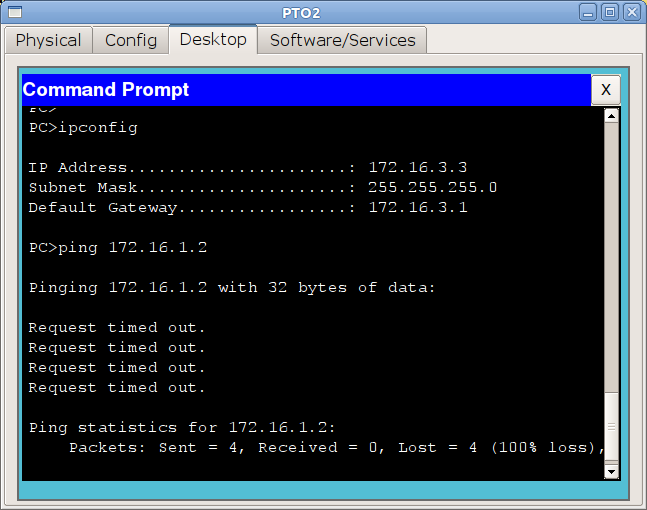
Материалы выпуска
Новый IP-план, планы коммутации по каждой точке и регламент
Файл РТ с лабораторной
Конфигурация устройств
Приносим извинения за гигантские простыни, видео тоже с каждым разом становится всё длиннее и невыносимее. Постараемся в следующий раз быть более компактными.
Все заинтересованные, но незарегистрированные приглашаются на беседу в ЖЖ.
За подготовку статьи большое спасибо моему соавтору thegluck и моей жене за львиное терпение.
Для очень недовольных: эта статья не абсолют, она не раскрывает теоретические аспекты в полной мере и, потому не претендует на роль полноценной документации. С точки зрения авторов это вспомогательной средство для новичков, волшебный стимул, если желаете. На хабре у вас есть возможность поставить минус, а не доказывать нашу неправоту. Прошу вас, поступите именно так, потому что ваши недовольства встретят лишь вышеприведённые аргументы.
Для очень недовольных: эта статья не абсолют, она не раскрывает теоретические аспекты в полной мере и, потому не претендует на роль полноценной документации. С точки зрения авторов это вспомогательной средство для новичков, волшебный стимул, если желаете. На хабре у вас есть возможность поставить минус, а не доказывать нашу неправоту. Прошу вас, поступите именно так, потому что ваши недовольства встретят лишь вышеприведённые аргументы.